Linux网络服务
相关网络配置的文件
网卡名配置相关文件
网卡名命名规则文件:
cat /etc/udev/rules.d/70-persistent-net.rules
# PCI device 0x8086:0x100f (e1000)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:db:c9:5c", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0"
PCI device 0x8086:0x100f (e1000)
SUBSYSTEM"net", ACTION"add", DRIVERS"?*", ATTR{address}"00:0c:29:db:c9:66", ATTR{type}"1", KERNEL"eth*", NAME="eth1"修改网卡命名示例
#1、查看网卡的驱动并且卸载网卡驱动
[root@rhel6 ~]# ethtool -i eth0
driver: e1000 #网卡驱动
[root@rhel6 ~]# modprobe -r e1000 #卸载网卡驱动
#修改70-persistent-net.rules文件
#重新加载网卡驱动并且重启网络服务
[root@rhel6 ~]# modprobe e1000 #重新加载网卡驱动
[root@rhel6 ~]# /etc/rc.d/init.d/network restart #重启网络服务CentOS7.x网卡名改为传统命名方式
#修改/etc/default/grbu文件
# sed -i.bak -r 's/(GRUB_CMDLINE_LINUX=.*)"/\1 net.ifnames=0"/' /etc/default/grub
#生成新的grub配置文件并重启生效
grub2-mkconfig -o /etc/grub2.cfg
#网络配置相关文件
#网络配置参考文件:/usr/share/doc/initscripts-9.03.53/sysconfig.txt
#网卡的配置在:/etc/sysconfig/network-scripts/下,配置文件:ifcfg-网卡名
[root@rhel6 ~]# cat /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0BOOTPROTO=static|dhcp|none
IPADDR=192.168.0.6NETMASK=255.255.255.0
#PREFIX=24 #子网掩码
GATEWAY=192.168.0.1
DNS1=114.114.114.114
DNS2=8.8.8.8
DNS3=1.1.1.1
TYPE=EthernetON
BOOT=yes
HWADDR=00:0C:29:DB:C9:5C
#MACADDR=00:0C:29:DB:C9:5A
#修改MAC地址UUID=38d329c5-b1bb-491b-a669-47422cfda764
NM_CONTROLLED=no网络配置文件常用配置参数详解:
DEVICE:此配置文件应用到的设备
HWADDR:对应的设备的MAC地址
BOOTPROTO:激活此设备时使用的地址配置协议,常用的dhcp, static, none, bootp
NM_CONTROLLED:NM是NetworkManager的简写,此网卡是否接受NM控制;建议为“no”(NetworkManager:图形界面的网络配置工具,不支持桥接,强烈建议关闭)
ONBOOT:在系统引导时是否激活此设备
TYPE:接口类型,常见有的Ethernet, Bridge
UUID:设备的惟一标识
IPADDR:指明IP地址
NETMASK:子网掩码
GATEWAY: 默认网关
DNS1:第一个DNS服务器指向
DNS2:第二个DNS服务器指向
USERCTL:普通用户是否可控制此设备
PEERDNS:如果BOOTPROTO的值为“dhcp”,是否允许dhcp server分配的dns服务器指向信息直接覆盖至/etc/resolv.conf文件中
其他相关配置文件
路由配置文:/etc/sysconfig/network-scripts/route-interface
NETWOEK/NETMASK via GATEWAY
DNS配置文件:/etc/resolv.conf
nameserver DNS_IP
本地网络解析配置文件:/etc/hosts
IP hostname alias
主机名配置文件:
centos6.x:/etc/sysconfig/network
centos7.x:/etc/hostname
关于网络的配置Tools
ifconfig
-a:查看启用和被禁用的网卡信息
interface {up|down}:启用或禁用网卡
interface IP/NETMASK:临时设置IP
interface [-]promisc:设置网卡的工作在混杂模式
-s interface:查看指定网卡的流量信息
route
-n:以数字方式显示,不解析,提高效率
add {-net | -host} NETWORK/NETMASK gw GATEWAY dev DEVICE 添加路由
{add | del} default gw GATEWAY 添加或删除默认路由
del {-net | -host} NETWORK/NETMASK gw GATEWAY 删除路由
route add -net 10.0.0.0/8 gw 172.20.0.1 dev eth1 #添加一条到10.0.0.0网段的路由
route del -net 10.0.0.0/8 gw 172.20.0.1 #删除10.0.0.0网段的路由netstat
-n:以数字方式显示,不解析,提高效率
-r:查看路由表
-t:TCP相关
-u:UDP相关
-w:裸套接字
-l:查看处于监听状态的端口
-a:查看所有状态的端口
-e:显示更详细的信息
-p:查看相关的进程PID
-i:显示网卡流量
-Iinterface:查看指定网卡的流量信息 == ifconfig -s interface
[root@centos7 ~]# netstat -tnulp #显示TCP,UDP的监听状态及相关进程的端口 ip
link
set interface {up|down}:启用或禁用网卡
show interface:显示指定网卡信息
addr
add IP/NETMASK [label interface:#] [scope {global | link | host}] [broadcast IP] dev interface:添加配置临时地址
label:指定别名
scope:作用域
global:作用域为全局
link:仅和此网卡相连的网络生效
host:仅主机可用
broadcast:设定广播地址
del dev interface [label interface:#]:删除IP
flush dev interface [label interface:#]:清空IP
route
add IP/NETMASK via GATEWAY dev interface:添加路由
add default via GATEWAY dev interface:添加默认路由
del IP/NETMASK via GATEWAY dev interface:删除路由
flush:清空路由表
show:查看路由表
root@centos7 ~]# ip addr add 192.168.1.100/24 label eth0:0 dev eth0 #设置临时IP地址ss
-n:以数字方式显示,不解析,提高效率
-t:TCP相关
-u:UDP相关
-w:裸套接字
-x:显示unix sock相关信息
-l:查看处于监听状态的端口
-a:查看所有状态的端口
-e:显示更详细的信息
-p:查看相关的进程PID
-m:内存用量
-o:计时器信息
-s:显示当前socket详细信息
state TCP_STATE '( dport = :ssh or sport = :ssh )'
established
listen
fin_wait_1
fin_wait_2
syn_sent
syn_recv
[root@centos7 ~]# ss state established '( dport = :ssh or sport = :ssh )' #查看已连接状态的sshnmcli:地址配置工具(CentOS7.x)
子命令补全功能:yum install bash-completion ,依赖epel源
1、查看信息
[root@centos7 ~]# nmcli device status
[root@centos7 ~]# nmcli connection show2、删除配置
[root@centos7 ~]# nmcli connection delete ens333、增加配置
[root@centos7 ~]# nmcli connection add con-name ens33 ifname ens33 type ethernet ipv4.method auto connection.autoconnect yescon-name ens33:配置文件名称
ifname ens33:指定网卡设备
type ethernet:网络类型以太网
ipv4.method auto:自动获取IP
connection.autoconnect yes:开机自启动
4、切换配置
[root@centos7 ~]# nmcli connection up ens335、修改配置文件名ens33 --> ens33-static
[root@centos7 ~]# nmcli connection modify ens33 con-name ens33-static6、修改配置IP
[root@centos7 ~]# nmcli connection modify ens33-static ipv4.addresses 192.168.0.100/24 ipv4.gateway 192.168.0.1 ipv4.method manualipv4.addresses 192.168.0.100/24:IP地址
ipv4.gateway 192.168.0.1:网关
ipv4.method manual:手动获取,静态地址必须配置为手动,否则默认动态
7、重新读取配置文件
[root@centos7 ~]# nmcli connection reload8、断开和连接网络连接
[root@centos7 ~]# nmcli device disconnect ens33
[root@centos7 ~]# nmcli device connect ens339、查看网络配置的详细信息
[root@centos7 ~]# nmcli connection show ens3310、在配置中再添加一个地址
[root@centos7 ~]# nmcli connection modify ens33-static +ipv4.addresses 10.0.0.2/8其他相关工具
ping:测试网络命令
-c count:ping的次数
-W timeout:超时时间,配合-c使用
-I ipaddress:指定用自己主机的IP去ping对方主机
-s size:每次ping发出的数据包大小,最大值65507
-f:竭尽自己主机的能力发出数据包
[root@centos7 ~]# ping -c1 -W1 192.168.0.6 #脚本中常用的ping测试,ping一次,超时时间1s
[root@centos7 ~]# ping -s 65507 -f 192.168.0.6 #竭尽自己所能,向192.168.0.6发出大数据包,ddos攻击tcpdump:抓包工具
-n:禁止解析IP
-i interface:指定网卡接口
tcp|udp|icmp|arp:指定包协议
mtr:网络诊断工具
traceroute:跟踪路由
tracepath:跟踪路由
ifup:启用网卡
ifdown:禁用网卡
setup:字符界面配置工具(centos6.x)
system-config-network-tui:字符界面网络配置工具(centos6.x)
hostnamectl:设置主机名工具(centos7.x)
status
set-hostname HOSTNAME
mm-connection-editor:图形界面网络配置工具(centos7.x)
nmtui:字符界面配置工具(centos7.x)
nmtui-connect
nmtui-edit
nmtui-hostname
lftp | lftp [-u user[,pass]] [-p port] [-e cmd] FTPSERVER:FTP客户端工具
get
mget
put
mput
mirror DIR
lftpget URL:非交互式下载ftp服务器的文件
wget:网络下载工具
-q:静默模式
-c:断点续传
-P /path/DIRNAME:下载的文件保存到指定文件夹
-O /path/FILENAME:下载的文件保存到指定位置,并重命名
--limit-rate=# K|M:限速至# K|M
elinks | links:字符界面web浏览器
-source:查看网页源代码
-dump:只显示文字
Bonding和Team
Bonding
绑定:将多块网卡绑定同一IP地址对外提供服务,可以实现高可用或者负载均衡。
工作模式:
mode 0:balance-rr 轮调策略:多张网卡可以轮流发数据包,实现负载均衡的功能
mode 1:active-backup 主备策略:其中active网卡的发数据包,其他备用
mode 3:broadcast 广播策略:每个网卡都会发一份包
配置示例:
1、创建bonding的设备配置文件
# cat >/etc/sysconfig/network-scripts/ifcfg-bond0 <<EOF
DEVICE=bond0
BOOTPROTO=none
BONDING_OPTS="miimon=100 mode=1"
IPADDR=192.168.0.6
PREFIX=24
EOFmiimon=100:每100ms进行一次链路检测
2、配置bonding的从属网卡
[root@rhel6 ~]# cat >/etc/sysconfig/network-scripts/ifcfg-eth0 <<EOF
DEVICE=eth0
BOOTPROTO=none
MASTER=bond0
SLAVE=yes
EOF
[root@rhel6 ~]# cat >/etc/sysconfig/network-scripts/ifcfg-eth1 <<EOF
DEVICE=eth1
BOOTPROTO=none
MASTER=bond0
SLAVE=yes
EOF3、重启网络服务并查看bonding状态
# /etc/rc.d/init.d/network restart
[root@rhel6 ~]# cat /proc/net/bonding/bond0 |head
Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011)
Bonding Mode: fault-tolerance (active-backup)
Primary Slave: None
Currently Active Slave: eth0 #现在eth0在工作状态
MII Status: up
MII Polling Interval (ms): 100
Up Delay (ms): 0
Down Delay (ms): 0删除bonding配置示例:
1、禁用bond0并卸载bonding模块
# ip link set bond0 down
# modprobe -r bonding2、还原配置文件,重启网络
附:官方文档链接
Team
网络组:是将多个网卡聚合在一起方法,从而实现冗错和提高吞吐量。
工作模式:runner
broadcast:广播
roundrobin:轮调
activebackup:主备
1、创建一个网络组接口
[root@centos7 ~]# nmcli connection add type team con-name team0 ifname team0 config '{"runner":{"name":"activebackup"}}'2、配置team0
[root@centos7 ~]# nmcli connection modify team0 ipv4.addresses 172.20.108.244/16 ipv4.method manual ipv4.gateway 172.20.0.13、创建port接口
[root@centos7 ~]# nmcli connection add con-name team0-eth1 type team-slave ifname eth1 master team0
[root@centos7 ~]# nmcli connection add con-name team0-eth2 type team-slave ifname eth2 master team04、启动team0及从属接口
[root@centos7 ~]# nmcli connection up team0
[root@centos7 ~]# nmcli connection up team0-eth1
[root@centos7 ~]# nmcli connection up team0-eth25、查看工作状态
[root@centos7 ~]# teamdctl team0 state6、配置文件示例:
ifcfg-team0配置文件
7、删除team0
[root@centos7 ~]# nmcli connection down team0
[root@centos7 ~]# nmcli connectioni delete team0-eth0
[root@centos7 ~]# nmcli connectioni delete team0-eth1Bridge
桥接:把一台机器上的若干个网络接口“连接”起来。其结果是,其中一个网口收到的报文会被复制给其他网口并发送出去。以使得网口之间的报文能够互相转发。网桥就是这样一个设备,它有若干个网口,并且这些网口是桥接起来的。与网桥相连的主机就能通过交换机的报文转发而互相通信。
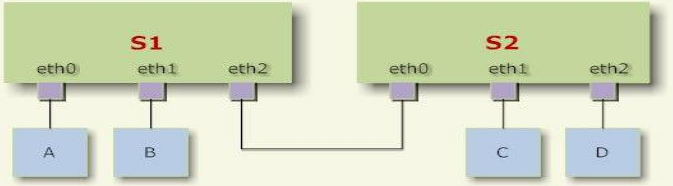
主机A发送的报文被送到交换机S1的eth0口,由于eth0与eth1、eth2桥接在一起,故而报文被复制到eth1和eth2,并且发送出去,然后被主机B和交换机S2接收到。而S2又会将报文转发给主机C、D。
1、创建一个网桥
[root@centos7 ~]# nmcli connection add type bridge con-name br0 ifname br02、配置网桥
[root@centos7 ~]# nmcli connection modify br0 ipv4.addresses 192.168.0.7/24 ipv4.method manual3、将从属网卡加入网桥
[root@centos7 ~]# nmcli connection add type bridge-slave con-name br0-eth0 ifname eth0 master br0 4、启用网桥并查看状态
[root@centos7 ~]# nmcli connection up br0
[root@centos7 ~]# nmcli connection up br0-eth0
[root@centos7 ~]# brctl show
bridge name bridge id STP enabled interfaces
br0 8000.000c295df21e yes eth05、配置文件示例:
[root@centos7 ~]# cat /etc/sysconfig/network-scripts/ifcfg-br0
DEVICE=br0
STP=yes
BRIDGING_OPTS=priority=32768
TYPE=Bridge
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=none
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=br0
UUID=94582afc-01a1-406d-a25a-91be7c350c23
ONBOOT=yes
IPADDR=192.168.0.7
PREFIX=24
[root@centos7 ~]# cat /etc/sysconfig/network-scripts/ifcfg-br0-eth0
TYPE=Ethernet
NAME=br0-eth0
UUID=9dd2a7fc-f143-4243-89ca-85f223e34348
DEVICE=eth0
ONBOOT=yes
BRIDGE=br0Linux网络虚拟化技术
Linux的网络虚拟化是LXC项目中的一个子项目,LXC包括文件系统虚拟化,进程空间虚拟化,用户虚拟化,网络虚拟化,等等,这里使用LXC的网络虚拟化来模拟多个网络环境。
Network Namespace
Network Namespace 是 Linux 内核提供的功能,是实现网络虚拟化的重要功能,它能创建多个隔离的网络空间,它们有独自网络栈信息。不管是虚拟机还是容器,运行的时候仿佛自己都在独立的网络中。而且不同Network Namespace的资源相互不可见,彼此之间无法通信。如下图所示:
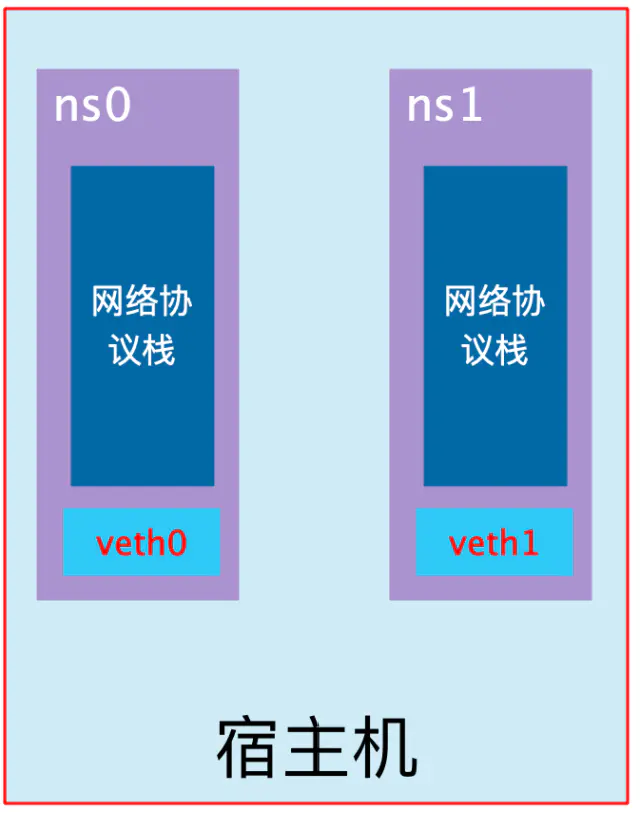
Network
ip netns命令
可以借助ip netns命令来完成对 Network Namespace 的各种操作。ip netns命令来自于iproute2安装包,一般系统会默认安装,如果没有的话,读者自行安装。
注意:ip netns命令修改网络配置时需要 sudo 权限。
可以通过ip netns命令完成对Network Namespace 的相关操作,可以通过ip netns help查看命令帮助信息:
$ ip netns help
Usage: ip netns list
ip netns add NAME
ip netns set NAME NETNSID
ip [-all] netns delete [NAME]
ip netns identify [PID]
ip netns pids NAME
ip [-all] netns exec [NAME] cmd ...
ip netns monitor
ip netns list-id创建Network Namespace
下面,我们通过命令创建一个名为ns0的命名空间:
$ ip netns add ns0
$ ip netns list
ns0 新创建的 Network Namespace 会出现在/var/run/netns/目录下。如果相同名字的 namespace 已经存在,命令会报Cannot create namespace file "/var/run/netns/ns0": File exists的错误。
对于每个 Network Namespace 来说,它会有自己独立的网卡、路由表、ARP 表、iptables 等和网络相关的资源。
操作Network Namespace
ip命令提供了ip netns exec子命令可以在对应的 Network Namespace 中执行命令。
查看新创建 Network Namespace 的网卡信息
$ ip netns exec ns0 ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00可以看到,新创建的Network Namespace中会默认创建一个lo回环网卡,此时网卡处于关闭状态。此时,尝试去 ping 该lo回环网卡,会提示Network is unreachable
$ ip netns exec ns0 ping 127.0.0.1
connect: Network is unreachable通过下面的命令启用lo回环网卡:
ip netns exec ns0 ip link set lo up然后再次尝试去 ping 该lo回环网卡:
$ ip netns exec ns0 ping -c 3 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.048 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.031 ms
64 bytes from 127.0.0.1: icmp_seq=3 ttl=64 time=0.029 ms
--- 127.0.0.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1999ms
rtt min/avg/max/mdev = 0.029/0.036/0.048/0.008 ms转移设备
我们可以在不同的 Network Namespace 之间转移设备(如veth)。由于一个设备只能属于一个 Network Namespace ,所以转移后在这个 Network Namespace 内就看不到这个设备了。
其中,veth设备属于可转移设备,而很多其它设备(如lo、vxlan、ppp、bridge等)是不可以转移的。
veth pair
veth pair 全称是 Virtual Ethernet Pair,是一个成对的端口,所有从这对端口一 端进入的数据包都将从另一端出来,反之也是一样。
引入veth pair是为了在不同的 Network Namespace 直接进行通信,利用它可以直接将两个 Network Namespace 连接起来。
整个veth的实现非常简单,有兴趣的读者可以参考源代码drivers/net/veth.c的实现。
veth pair
创建veth pair
$ sudo ip link add type veth
$ ip addr
61: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether e6:39:e1:e0:3a:a0 brd ff:ff:ff:ff:ff:ff
62: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether be:41:49:42:23:6a brd ff:ff:ff:ff:ff:ff可以看到,此时系统中新增了一对veth pair,将veth0和veth1两个虚拟网卡连接了起来,此时这对 veth pair 处于”未启用“状态。
如果我们想指定 veth pair 两个端点的名称,可以使用下面的命令:
ip link add vethfoo type veth peer name vethbar实现Network Namespace间通信
下面我们利用veth pair实现两个不同的 Network Namespace 之间的通信。刚才我们已经创建了一个名为ns0的 Network Namespace,下面再创建一个信息Network Namespace,命名为ns1
$ ip netns add ns1
$ ip netns list
ns1
ns0然后我们将veth0加入到ns0,将veth1加入到ns1,如下所示:
$ ip link set veth0 netns ns0
$ ip link set veth1 netns ns1然后我们分别为这对veth pair配置上ip地址,并启用它们:
$ ip netns exec ns0 iplink set veth0 up
$ ip netns exec ns0 ip addr add 10.0.1.1/24 dev veth0
$ ip netns exec ns1 iplink set veth1 up
$ ip netns exec ns1 ip addr add 10.0.1.2/24 dev veth1查看这对veth pair的状态
$ ip netns exec ns0 ip addr
61: veth0@if62: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether e6:39:e1:e0:3a:a0 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet 10.0.1.1/24 scope global veth0
valid_lft forever preferred_lft forever
inet6 fe80::e439:e1ff:fee0:3aa0/64 scope link
valid_lft forever preferred_lft forever
$ ip netns exec ns1 ip addr
62: veth1@if61: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether be:41:49:42:23:6a brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.1.2/24 scope global veth1
valid_lft forever preferred_lft forever
inet6 fe80::bc41:49ff:fe42:236a/64 scope link
valid_lft forever preferred_lft forever从上面可以看出,我们已经成功启用了这个veth pair,并为每个veth设备分配了对应的ip地址。我们尝试在ns1中访问ns0中的ip地址:
$ ip netns exec ns1 ping -c 3 10.0.1.1
sudo: unable to resolve host zormshogu
PING 10.0.1.1 (10.0.1.1) 56(84) bytes of data.
64 bytes from 10.0.1.1: icmp_seq=1 ttl=64 time=0.091 ms
64 bytes from 10.0.1.1: icmp_seq=2 ttl=64 time=0.035 ms
64 bytes from 10.0.1.1: icmp_seq=3 ttl=64 time=0.037 ms
--- 10.0.1.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1999ms
rtt min/avg/max/mdev = 0.035/0.054/0.091/0.026 ms可以看到,veth pair成功实现了两个不同Network Namespace之间的网络交互。
veth查看对端
一旦将veth pair的peer段放入另一个Network Namespace,我们在当前Namespace中就看不到它了。那么,我们怎么才能知道这个veth pair的对端在哪里呢?
可以通过ethtool工具来查看(当Network Namespace很多时,操作会比较麻烦):
$ ip netns exec ns1 ethtool -S veth1
NIC statistics:
peer_ifindex: 5得知另一端的接口设备序列号是5,我们再到另一个命名空间中查看序列号5代表什么设备:
$ ip netns exec ns0 ip link | grep 5
veth0网桥
veth pair打破了 Network Namespace 的限制,实现了不同 Network Namespace 之间的通信。但veth pair有一个明显的缺陷,就是只能实现两个网络接口之间的通信。
如果我们想实现多个网络接口之间的通信,就可以使用下面介绍的网桥(Bridge)技术。
简单来说,网桥就是把一台机器上的若干个网络接口“连接”起来。其结果是,其中一个网口收到的报文会被复制给其他网口并发送出去。以使得网口之间的报文能够互相转发。
网桥的工作原理
网桥对报文的转发基于MAC地址。网桥能够解析收发的报文,读取目标MAC地址的信息,和自己记录的MAC表结合,来决策报文的转发目标网口。
为了实现这些功能,网桥会学习源MAC地址,在转发报文时,网桥只需要向特定的网口进行转发,从而避免不必要的网络交互。
如果它遇到一个自己从未学习到的地址,就无法知道这个报文应该向哪个网口转发,就将报文广播给所有的网口(报文来源的网口除外)。
网桥
网桥的实现
Linux内核是通过一个虚拟的网桥设备(Net Device)来实现桥接的。这个虚拟设备可以绑定若干个以太网接口设备,从而将它们桥接起来。如下图所示:
网桥的位置
如上图所示,网桥设备 br0 绑定了 eth0 和 eth1。
对于网络协议栈的上层来说,只看得到 br0,上层协议栈需要发送的报文被送到 br0,网桥设备的处理代码判断报文该被转发到 eth0 还是 eth1,或者两者皆转发;反过来,从eth0 或 eth1 接收到的报文被提交给网桥的处理代码,在这里会判断报文应该被转发、丢弃还是提交到协议栈上层。
而有时eth0、eth1 也可能会作为报文的源地址或目的地址,直接参与报文的发送与接收,从而绕过网桥。
brctl
和网桥有关的操作可以使用命令 brctl,这个命令来自 bridge-utils 这个包。
创建网桥
# 创建网桥
brctl addbr br0 删除网桥
# 删除网桥
brctl delbr br0绑定网口
建立一个逻辑网段之后,我们还需要为这个网段分配特定的端口。在Linux 中,一个端口实际上就是一个物理或虚拟网卡。而每个网卡的名称则分别为eth0 ,eth1 ,eth2 。我们需要把每个网卡一一和br0 这个网段联系起来,作为br0 中的一个端口。
# 让eth0 成为br0 的一个端口
brctl addif br0 eth0
# 让eth1 成为br0 的一个端口
brctl addif br0 eth1
# 让eth2 成为br0 的一个端口
brctl addif br0 eth2iptables/netfilter
iptables是Linux实现的软件防火墙,用户可以通过iptables设置请求准入和拒绝规则,从而保护系统的安全。
我们也可以把iptables理解成一个客户端代理,用户通过iptables这个代理,将用户安全设定执行到对应的安全框架中,这个“安全框架”才是真正的防火墙,这个框架的名字叫netfilter。
iptables其实是一个命令行工具,位于用户空间。
iptables/netfilter(以下简称iptables)组成了Linux平台下的包过滤防火墙,可以完成封包过滤、封包重定向和网络地址转换(NAT)等功能。
消息处理链
iptables不仅要处理本机接收到的消息,也要处理本机发出的消息。这些消息需要经过一系列的”关卡“才能被本机应用层接收,或者从本机发出,每个”关卡“担负着不同的工作。这里的”关卡“被称为”链“。
INPUT:进来的数据包应用此规则链中的策规则;OUTPUT:外出的数据包应用此规则链中的规则;FORWARD:转发数据包时应用此规则链中的规则;PREROUTING:对数据包作路由选择前应用此链中的规则(所有的数据包进来的时侯都先由这个链处理);POSTROUTING:对数据包作路由选择后应用此链中的规则(所有的数据包出来的时侯都先由这个链处理);
数据包经过各个链的处理过程大致如下图所示:
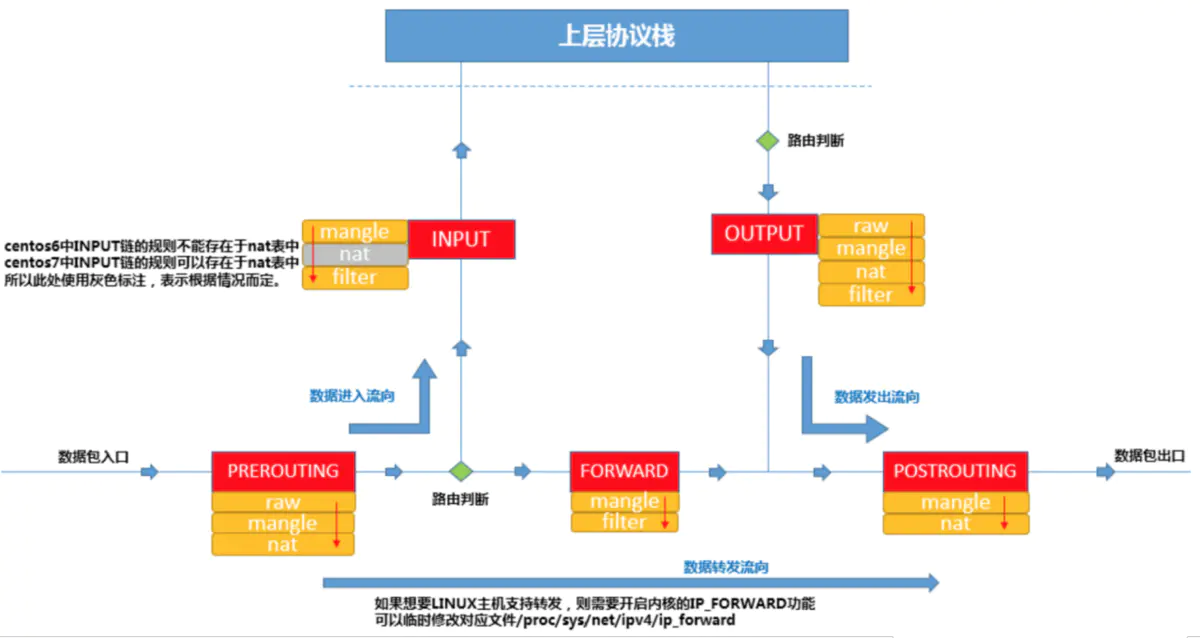
消息处理链
规则表
从上面我们知道,iptables是按照规则来办事的,这些规则就是网络管理员预定义的条件。规则一般的定义为:如果数据包头符合这样的条件,就这样处理“。这些规则并不是严格按照添加顺序排列在一张规则表中,而是按照功能进行分类,存储在不同的表中,每个表存储一类规则:
Filter
主要用来过滤数据,用来控制让哪些数据可以通过,哪些数据不能通过,它是最常用的表。
NAT
用来处理网络地址转换的,控制要不要进行地址转换,以及怎样修改源地址或目的地址,从而影响数据包的路由,达到连通的目的。
Mangle
主要用来修改IP数据包头,比如修改TTL值,同时也用于给数据包添加一些标记,从而便于后续其它模块对数据包进行处理(这里的添加标记是指往内核skb结构中添加标记,而不是往真正的IP数据包上加东西)。
Raw
在Netfilter里面有一个叫做链接跟踪的功能,主要用来追踪所有的连接,而raw表里的rule的功能是给数据包打标记,从而控制哪些数据包不做链接跟踪处理,从而提高性能;
优先级最高。
表和链的关系
表和链共同完成了iptables对数据包的处理。但并不是每个链都包含所有类型的表,所以,有些链是天生不具备某些功能的。就像我们去车站乘车的时候,”关卡A“只负责检查身份证,”B关卡”只负责检查行李,而“C关卡”功能比较齐全,即负责检查身份证,又负责检查行李。二者的关系如下图所示:
表和链的关系
总结
今天我们共同学习了一些常见的Linux虚拟网络技术。其中,Linux通过Network Namespace实现了网络的隔离,使网络协议栈之间互不干扰;并通过veth pair和网桥实现了相同主机上多个Network Namespace之间的数据通信;iptables则可以帮助我们实现网络安全和数据包的路由转发功能,从而使主机和主机、容器与容器、容器和宿主机之间可以相互收发消息。在这些技术的共同协作下,才有了现在安全、稳定的虚拟网络。
TUN 设备
TUN 设备是一种虚拟网络设备,通过此设备,程序可以方便得模拟网络行为。先来看看物理设备是如何工作的:
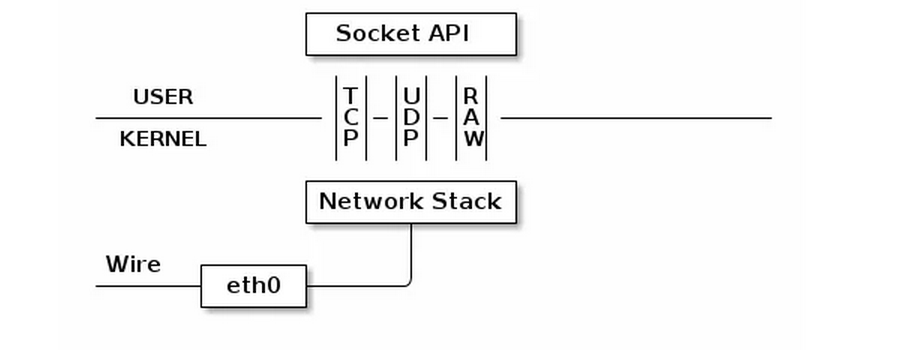
所有物理网卡收到的包会交给内核的 Network Stack 处理,然后通过 Socket API 通知给用户程序。下面看看 TUN 的工作方式:
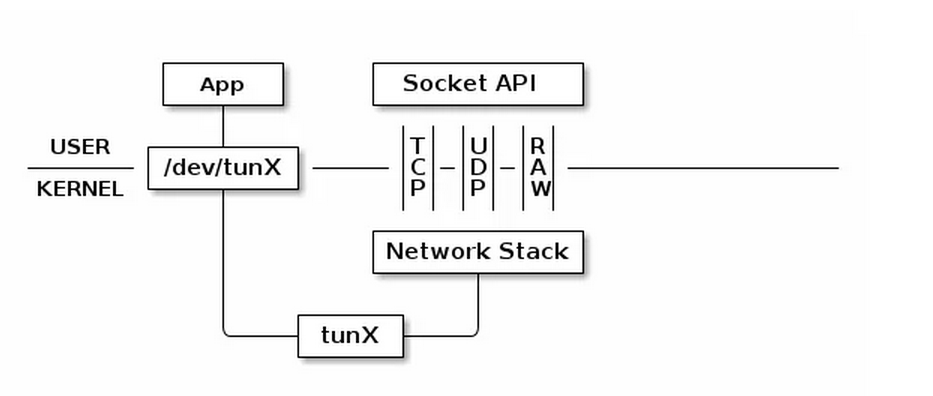
普通的网卡通过网线收发数据包,但是 TUN 设备通过一个文件收发数据包。所有对这个文件的写操作会通过 TUN 设备转换成一个数据包送给内核;当内核发送一个包给 TUN 设备时,通过读这个文件可以拿到包的内容。 如果我们使用 TUN 设备搭建一个基于 UDP VPN,那么整个处理过程就是这样:
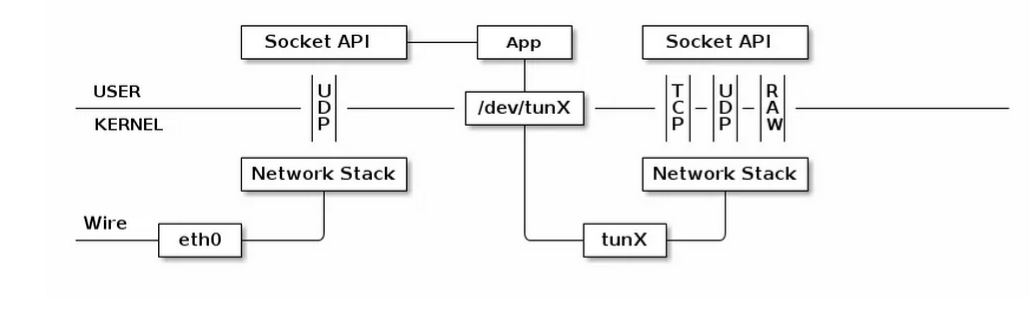
数据包会通过内核网络栈两次。但是经过 App 的处理后,数据包可能已经加密,并且原有的 ip 头被封装在 udp 内部,所以第二次通过网络栈内核看到的是截然不同的网络包。
TAP 设备
TAP 设备与 TUN 设备工作方式完全相同,区别在于: TUN 设备的 /dev/tunX 文件收发的是 IP 层数据包,只能工作在 IP 层,无法与物理网卡做 bridge,但是可以通过三层交换(如 ip_forward)与物理网卡连通。 TAP 设备的 /dev/tapX 文件收发的是 MAC 层数据包,拥有 MAC 层功能,可以与物理网卡做 bridge,支持 MAC 层广播。
MACVLAN 有时我们可能需要一块物理网卡绑定多个 IP 以及多个 MAC 地址,虽然绑定多个 IP 很容易,但是这些 IP 会共享物理网卡的 MAC 地址,可能无法满足我们的设计需求,所以有了 MACVLAN 设备,其工作方式如下:
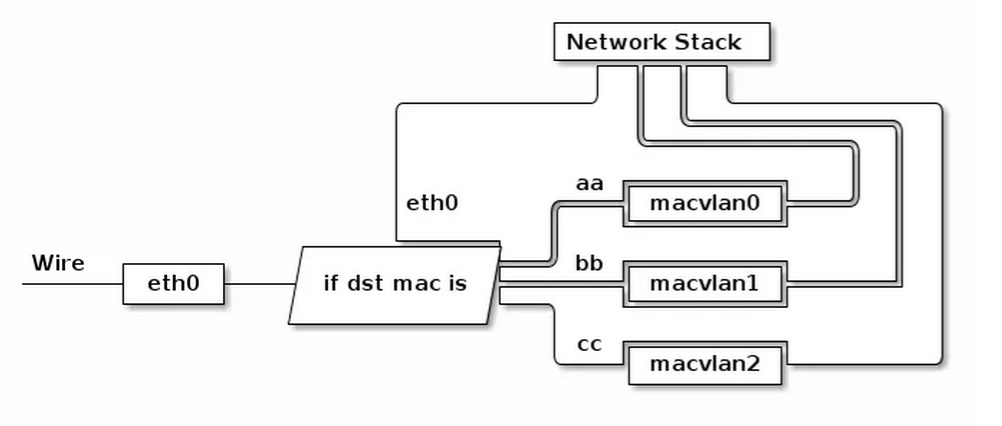
MACVLAN 会根据收到包的目的 MAC 地址判断这个包需要交给哪个虚拟网卡。单独使用 MACVLAN 好像毫无意义,但是配合之前介绍的 network namespace 使用,我们可以构建这样的网络:
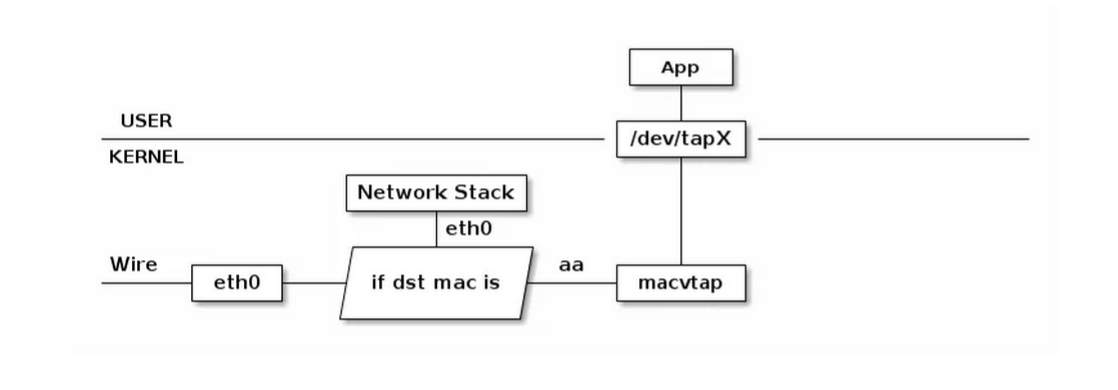
由于 macvlan 与 eth0 处于不同的 namespace,拥有不同的 network stack,这样使用可以不需要建立 bridge 在 virtual namespace 里面使用网络。
MACVTAP
MACVTAP 是对 MACVLAN的改进,把 MACVLAN 与 TAP 设备的特点综合一下,使用 MACVLAN 的方式收发数据包,但是收到的包不交给 network stack 处理,而是生成一个 /dev/tapX 文件,交给这个文件:
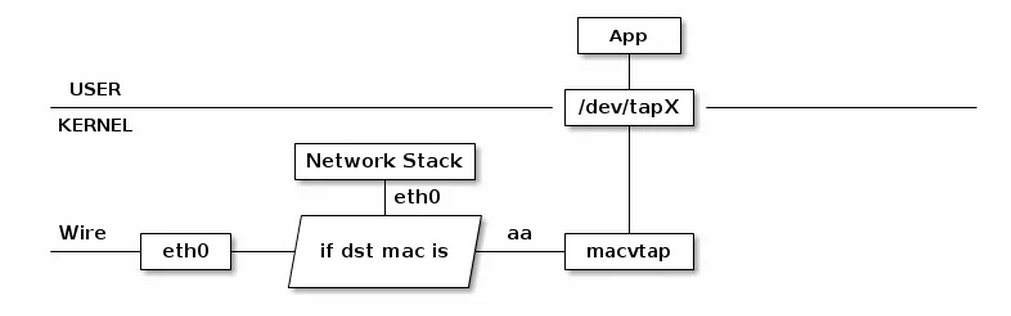
由于 MACVLAN 是工作在 MAC 层的,所以 MACVTAP 也只能工作在 MAC 层,不会有 MACVTUN 这样的设备。
创建虚拟网络环境
使用命令
$ ip netns add net0
#可以创建一个完全隔离的新网络环境,这个环境包括一个独立的网卡空间,路由表,ARP表,ip地址表,iptables,ebtables,等等。总之,与网络有关的组件都是独立的。
$ ip netns list net0
#进入虚拟网络环境
$ ip netns exec net0 `command`
#net0 虚拟环境中运行任何命令
$ ip netns exec net0 bash
$ ip ad
1: lo: mtu 65536 qdisc noop state DOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
#新的网络环境中打开一个shell,可以看到,新的网络环境里面只有一个lo设备,并且这个lo设备与外面的lo设备是不同的,之间不能互相通讯。
#连接两个网络环境
#新的网络环境里面没有任何网络设备,并且也无法和外部通讯,就是一个孤岛,通过下面介绍的这个方法可以把两个网络环境连起来,简单的说,就是在两个网络环境之间拉一根网线。
$ ip netns add net1
#创建另一个网络环境net1,我们的目标是把net0与net1连起来
$ ip link add type veth
$ ip ad 1: lo: mtu 65536 qdisc noop state DOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
81: veth0: mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 12:39:09:81:3a:dd brd ff:ff:ff:ff:ff:ff
82: veth1: mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 32:4f:fd:cc:79:1b brd ff:ff:ff:ff:ff:ff
#创建连一对veth虚拟网卡,类似pipe,发给veth0的数据包veth1那边会收到,发给veth1的数据包veth0会收到。就相当于给机器安装了两个网卡,并且之间用网线连接起来了。
$ ip link set veth0 netns net0
$ ip link set veth1 netns net1
#两条命令的意思就是把veth0移动到net0环境里面,把veth1移动到net1环境里面
$ ip ad
1: lo: mtu 65536 qdisc noop state DOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
$ ip netns exec net0 ip ad
1: lo: mtu 65536 qdisc noop state DOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
81: veth0: mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 12:39:09:81:3a:dd brd ff:ff:ff:ff:ff:ff
$ ip netns exec net1 ip ad
1: lo: mtu 65536 qdisc noop state DOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
82: veth1: mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 32:4f:fd:cc:79:1b brd ff:ff:ff:ff:ff:ff
#veth0 veth1已经在我们的环境里面消失了,并且分别出现在net0与net1里面。下面我们简单测试一下net0与net1的联通性。
$ ip netns exec net0 ip link set veth0 up
$ ip netns exec net0 ip address add 10.0.1.1/24 dev veth0
$ ip netns exec net1 ip link set veth1 up
$ ip netns exec net1 ip address add 10.0.1.2/24 dev veth1
#配置好两个设备,然后用ping测试一下联通性
$ ip netns exec net0 ping -c 3 10.0.1.2
PING 10.0.1.2 (10.0.1.2) 56(84) bytes of data.
64 bytes from 10.0.1.2: icmp_req=1 ttl=64 time=0.101 ms
64 bytes from 10.0.1.2: icmp_req=2 ttl=64 time=0.057 ms
64 bytes from 10.0.1.2: icmp_req=3 ttl=64 time=0.048 ms
--- 10.0.1.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1999ms
rtt min/avg/max/mdev = 0.048/0.068/0.101/0.025 ms
复杂的网络环境
创建虚拟网络环境并且连接网线
ip netns add net0
ip netns add net1
ip netns add bridge
ip link add type veth
ip link set dev veth0 name net0-bridge netns net0
ip link set dev veth1 name bridge-net0 netns bridge
ip link add type veth
ip link set dev veth0 name net1-bridge netns net1
ip link set dev veth1 name bridge-net1 netns bridge
#在bridge中创建并且设置br设备:
ip netns exec bridge brctl addbr br
ip netns exec bridge ip link set dev br up
ip netns exec bridge ip link set dev bridge-net0 up
ip netns exec bridge ip link set dev bridge-net1 up
ip netns exec bridge brctl addif br bridge-net0
ip netns exec bridge brctl addif br bridge-net1
#然后配置两个虚拟环境的网卡:
ip netns exec net0 ip link set dev net0-bridge up
ip netns exec net0 ip address add 10.0.1.1/24 dev net0-bridge
ip netns exec net1 ip link set dev net1-bridge up
ip netns exec net1 ip address add 10.0.1.2/24 dev net1-bridge
#测试:
$ ip netns exec net0
ping -c 3 10.0.1.2
PING 10.0.1.2 (10.0.1.2) 56(84) bytes of data.
64 bytes from 10.0.1.2: icmp_req=1 ttl=64 time=0.121 ms
64 bytes from 10.0.1.2: icmp_req=2 ttl=64 time=0.072 ms
64 bytes from 10.0.1.2: icmp_req=3 ttl=64 time=0.069 ms
--- 10.0.1.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1999ms
rtt min/avg/max/mdev = 0.069/0.087/0.121/0.025 ms
Linux 提供一个开关来操作路由功能,就是 /proc/sys/net/ipv4/ip_forward,默认这个开关是关的,打开只需:
echo 1 > /proc/sys/net/ipv4/ip_forward但这种打开方式只是临时的,如果要一劳永逸,可以修改配置文件 /etc/sysctl.conf,添加或修改项 net.ipv4.ip_forward 为:
net.ipv4.ip_forward = 1即可。
实践
为了降低大家实践的难度,我们就不创建虚拟机了,直接使用 namespace,一条 ip 命令就可以搞定所有的操作。
我们按照下面的图示进行操作(NS1 和 NS2 分布在不同网段):
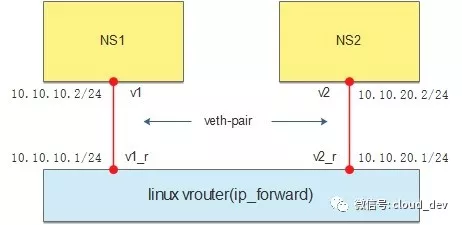
创建两个 namespace:
ip netns add ns1
ip netns add ns2创建两对 veth-pair,一端分别挂在两个 namespace 中:
ip link add v1 type veth peer name v1_r
ip link add v2 type veth peer name v2_r
ip link set v1 netns ns1
ip link set v2 netns ns2分别给两对 veth-pair 端点配上 IP 并启用:
ip a a 10.10.10.1/24 dev v1_r
ip l s v1_r up
ip a a 10.10.20.1/24 dev v2_r
ip l s v2_r up
ip netns exec ns1 ip a a 10.10.10.2/24 dev v1
ip netns exec ns1 ip l s v1 up
ip netns exec ns2 ip a a 10.10.20.2/24 dev v2
ip netns exec ns2 ip l s v2 up验证一下: v1 ping v2,结果不通。
看下 ip_forward 的值:
[root@by ~]# cat /proc/sys/net/ipv4/ip_forward
0没开路由怎么通,改为 1 再试,还是不通。
看下 ns1 的路由表:
[root@by ~]# ip netns exec ns1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.10.10.0 0.0.0.0 255.255.255.0 U 0 0 0 v1只有一条直连路由,没有去往 10.10.20.0/24 网段的路由,怎么通?那就给它配一条:
[root@by ~]# ip netns exec ns1 route add -net 10.10.20.0 netmask 255.255.255.0 gw 10.10.10.1
[root@by ~]# ip netns exec ns1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.10.10.0 0.0.0.0 255.255.255.0 U 0 0 0 v1
10.10.20.0 10.10.10.1 255.255.255.0 UG 0 0 0 v1同理也给 ns2 配上去往 10.10.10.0/24 网段的路由。
最后再 ping,成功了!
[root@by ~]# ip netns exec ns1 ping 10.10.20.2
PING 10.10.20.2 (10.10.20.2) 56(84) bytes of data.
64 bytes from 10.10.20.2: icmp_seq=1 ttl=63 time=0.071 ms
64 bytes from 10.10.20.2: icmp_seq=2 ttl=63 time=0.070 ms
^C
--- 10.10.20.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1000ms
rtt min/avg/max/mdev = 0.070/0.070/0.071/0.008 mslinux网络命令详解
ifconfig命令
格式:ifconfig {inerface} {options}
options参数有:up,down,mtu,netmask,broadcast
单独ifconfig命令:查看网络所有端口;
范例1:ifconfig eth0 192.168.1.0 netmask 255.255.0.0 mtu 8000(配置端口eth0的ip地址)
范例2:ifconfig eth0:0 192.168.50.50(表示在eth0再仿真出来一个网络接口)
注意:ifconfig 的配置只会暂时生效,机器重启或者/etc/init.d/network restart ,则会使ifconfig的配置无效;
ifup ifdown命令
格式:ifup interface ; ifdown interface
例如:ifup eth0;ifdown eth0
其实这两个命令是脚本 ,它们是去读取/etc/sysconfig/network-scripts/ifcfg-eth*文件;
route命令
格式:route或者route -n看路由信息
route add [-host 或者-net] netmask gw或者dev
route del [-host 或者-net] netmask gw或者dev
例子:route add -net 192.168.100.0 netmask 255.255.255.0 dev eth0
例子:route add default gw 192.168.1.250
注意:ifconfig eth0 192.168.1.0还是route add -net 192.168.1.0 mask 255.255.255.0 dev eth0 都是临时生效,用来联网和测试,等到测试完毕后,在使 用/etc/init.d/network restart 恢复原来默认网络即可;
4 ip命令比较强大
ip link设定
格式:ip link set [device ] [动作和参数]
例子:ip link show (单纯的看设备的相关硬件信息)
例子:ip link show eth0
例子:ip link set eth0 up ; ip link set eth0 down; ip link set eth0 mtu 1000(打开和关闭端口以及设备mtu)
例子:ip link set eth0 down> ip link set eth0 name vbird >ip link show(更改eth0的名字,改之前先网卡eth0)
ip address
格式:ip address [add|del] [ip] [dev] [相关参数]
例子:ip address show (eth*)
例子:ip address add 192.168.50.50/24 broadcast dev eth0 label eth0:vbird( 添加一个网络接口)
例子:ip address del 192.168.50.50/24 dev eth0
(ip route)
ip route show
例子:ip route add 192.168.5.0/24 dev eth0(添加路由,主要是本机直接可沟通的网络)
例子:ip route add 192.168.10.0/24 via 192.168.5.100 dev eth0 (添加可以通往外部的路由,需通过router)
例子:ip route add default via 192.168.1.254 dev eth0 (添加路由,通过192.168.1.254这台主机通信,事实上这台主机就是我的默认路由器(gateway))
例子:ip route del 192.168.5.0/24;ip route del 192.168.10.0/24 (删除路由)
无线网络命令:iwlist(无线网卡进行无线网络的AP的检测与取得相关数据) iwconfig(无线网卡的配置)
DHCP客户端命令:dhclient 如:dhclient eth0
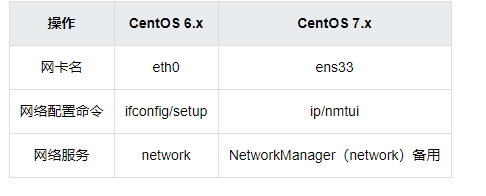
Centos6 对比Centos7
文件系统
CentOS 6.x
EXT4:单个文件系统容量达到1EB,单个文件大小达到16TB。
CentOS 7.x
XFS:默认支持8EB减1字节的单个文件系统,最大可支持的文件大小为9EB,最大文件系统尺寸为18EB。
防火墙
CentOS 6.x
iptables
CentOS 7.x
firewalled
内核版本
CentOS 6.x
2.6.x-x
CentOS 7.x
3.10.x-x
默认数据库
CentOS 6.x
MySQL
CentOS 7.x
MariaDB
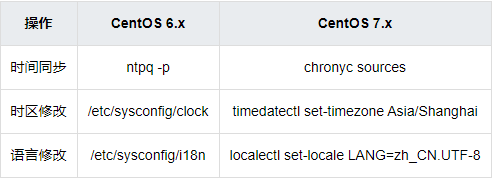
时间同步、时区修改、语言修改
主机名
CentOS 6.x
配置文件:/etc/sysconfig/network
CentOS 7.x
配置文件:/etc/hostname
hostnamectl set-hostname xxx
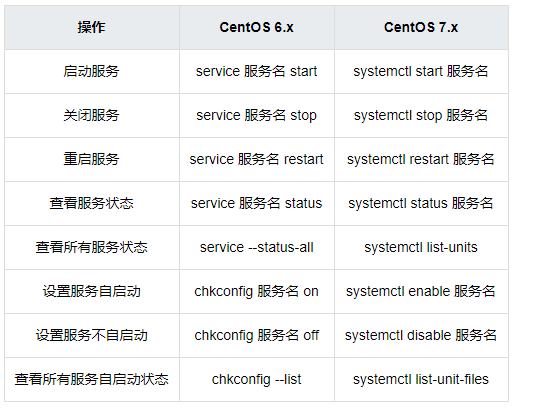
网络服务管理
网络设置
Centos7 配置文件/网卡改名
配置文件目录
/etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static #连接方式 dhcp/static
DEFROUTE=yes #启用默认路由
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33 #网卡名称
UUID=1d1fc3bd-363d-4875-a685-3564873e5b6b
DEVICE=ens33 #设备名称
ONBOOT=yes
IPADDR=192.168.137.200
NETMASK=255.255.255.0
GATEWAY=192.168.137.2
DNS1=192.168.137.2
配置管理命令
ifconfig / ip address show#修改网卡配置文件名(建议将原配置文件备份)
cp -a ifcfg-ens33 ifcfg-eth0
#修改网卡配置文件内容
NAME=eth0
DEVICE=eth0
#修改grub配置文件
vi /etc/default/grub
"GRUB_CMDLINE+LINUX=crashkernel=auto rhgb quiet net.ifnames=0 biosdevname=0"
#net.ifnames=0 biosdevname=0 在指定位置新增参数,关闭一致性命名规则
#更新grub配置文件,并加载新的参数
grub2-mkconfig -o /boot/grub2/grub.cfg
#重启操作系统
reboot常见的网络协议和端口
网络地址
网络地址(Network address)则是互联网上的节点在网络中具有的逻辑地址,可对节点进行寻址。IP地址是在互联网上给主机编址的方式,为每个计算机分配一个逻辑地址,这样不但能够对计算机进行识别,还能进行信息共享。
物理地址
网卡物理地址存储器中存储单元对应实际地址称物理地址,MAC(Media Access Control,介质访问控制)地址是识别LAN局域网节点的标识。在网络底层的物理传输过程中,是通过物理地址来识别主机主机)的,它一般也是全球唯一的
常见网络协议含义及端口
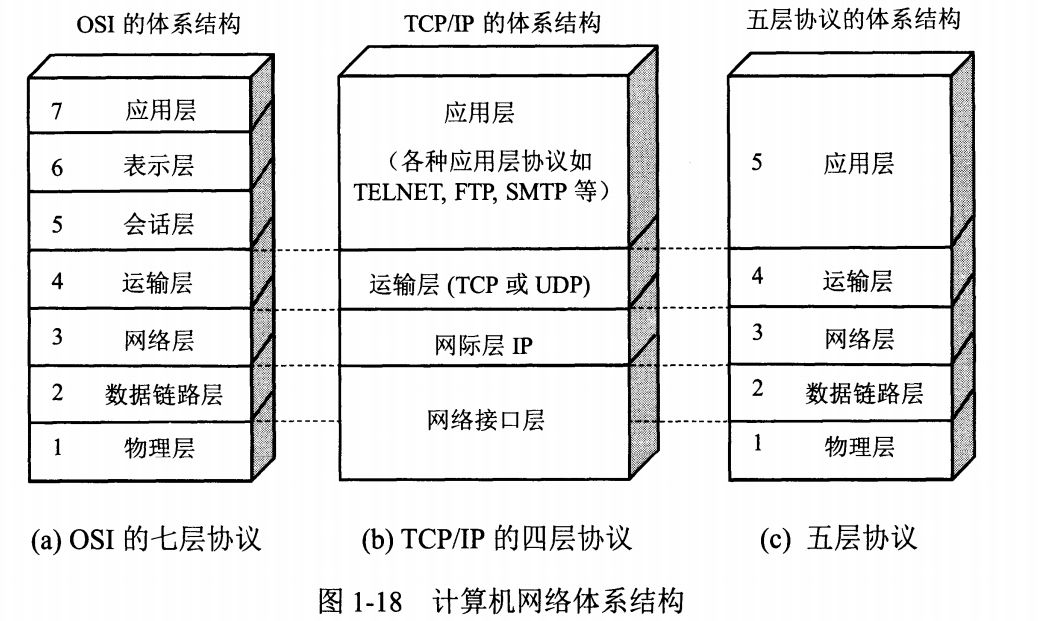
一、OSI模型
名称 层次 功能
物理层 1 实现计算机系统与网络间的物理连接
数据链路层 2 进行数据打包与解包,形成信息帧
网络层 3 提供数据通过的路由
传输层 4 提供传输顺序信息与响应
会话层 5 建立和中止连接
表示层 6 数据转换、确认数据格式
应用层 7 提供用户程序接口
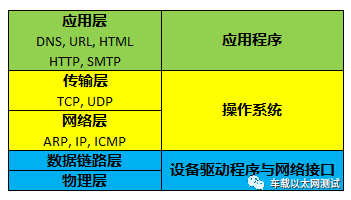
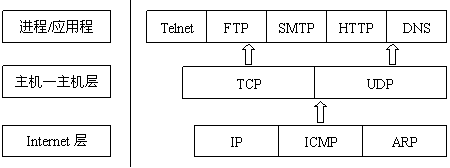
二、协议层次
网络中常用协议以及层次关系
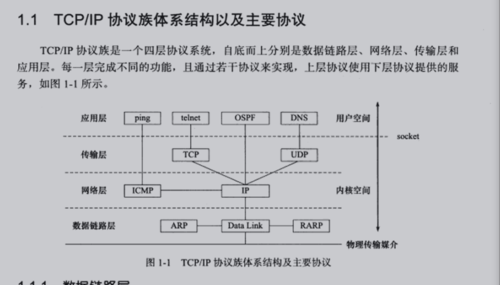
FTP(文件传输协议): 20/21
SSH(安全shell协议):22
telnet(远程登录协议):23
SMTP(简单邮件传输协议):25
DNS(域名解析系统):53
HTTP(超文本传输协议):80
POP3(邮局协议3代):110查看端口命令
windows cmd下
netstat -an 列出所有被打开的端口列表
netstat -ano 列出所有占用端口的列表linux下
netstat -ntlp:查看当前所有tcp端口
-t : 只显示TCP端口
-u : 只显示UDP端口Linux下网关路由配置
路由
路由(Routing):路由是指从一个设备(一般指路由器)的接口上接收到数据包,依据设备所既定的某些规则,将数据包转发到其它接口的 “过程”。路由工作在OSI参考模型第三层——网络层]网络层&spm=1001.2101.3001.7020)的数据包转发设备。路由器通过转发数据包来实现网络互连
路由器(Router):路由器是用于连接多个逻辑上分开的网络,所谓逻辑网络是代表一个单独的网络或者一个子网。当数据从一个子网传输到另一个子网时,可通过路由器的路由功能来完成。因此,路由器具有判断网络地址和选择IP路径的功能,它能在多网络互联环境中,建立灵活的连接,可用完全不同的数据分组和介质访问方法连接各种子网,路由器只接受源站或其他路由器的信息,属网络层的一种互联设备(能实现路由功能的设备,就叫路由器) 路由表(RouTIng InformaTIon Base )
路由表是指路由器或者其他互联网网络设备上存储的一张路由信息表,该表中存有到达特定网络终端的路径,在某些情况下,还有一些与这些路径相关的度量。(进行数据包路由时,所依据的 规则 集合。供路由时选择)
路由概念
路由:跨越从源主机到目标主机的一个互联网络来转发数据包的过程;
路由器:能够将数据包转发到正确的目的地,并在转发过程中选择最佳路径的设备;
路由表:在路由器中维护的路由条目,路由器根据路由表做路径选择;
直连路由:当在路由器上配置了接口的IP地址,并且接口状态为up的时候,路由表中就出现直连路由项;
静态路由:是由管理员手工配置的,是单向的;
默认路由:当路由器在路由表中找不到目标网络的路由条目时,路由器把请求转发到默认路由接口 。
静态路由和默认路由的特点
静态路由特点:
路由表是手工设置的;
除非网络管理员干预,否则静态路由不会发生变化;
路由表的形成不需要占用网络资源;
适用环境:一般用于网络规模很小、拓扑结构固定的网络中。
默认路由特点:
在所有路由类型中,默认路由的优先级最低;
适用环境:一般应用在只有一个出口的末端网络中或作为其他路由的补充
浮动静态路由:
路由表中存在相同目标网络的路由条目时,根据路由条目优先级的高低,将请求转发到相应端口;
链路冗余的作用;
路由器转发数据包时的封装过程
源IP和目标IP不发生变化,在网络的每一段传输时,源和目标MAC发生变化,进行重新封装,分别是每一段的源和目标地址
路由器的内容
目的地址;
相连路由器,并可以从那里获得远程网络的信息;
到所有远程网络的可能路由;
到达每个远程网络的最佳路由;
如何维护并验证路由信息;
路由和交换的对比。
路由工作在网络层
根据“路由表”转发数据;
路由选择;
路由转发。
交换工作在数据链路层
根据“MAC地址表”转发数据;
硬件转发。
策略路由&路由策略数据库
Internet上采用的路由算法一般是基于数据包目的地址的。而在某些情况下,我们不只是需要通过数据包的目的地址决定路由,可能还需要通过其他一些域:源地址、IP协议、传输层端口甚至数据包的负载。这就叫做:策略路由(policy routing)。
注意:策略路由(policy routing)不等于路由策略(rouing policy)。路由策略数据库(routing policy database,RPDB)
RPDB可以匹配以下的域:
数据包的源地址;
数据包的目的地址;
服务类型(Type of Service);
进入的网络接口。
每个路由策略由一个选择符(selector)和一个操作(action)组成。系统按照顺序搜索路由策略数据库,把选择符和{源地址、目的地址、进入 接口、tos、fwmark}等关键词进行匹配,如果匹配成功,就执行action定义的操作。操作或者成功返回,或者失败并且中止对路由策略。否则,系统继续查询路由策略数据库。
[root@bogon ~]# ip rule
0: from all lookup local #0 匹配任何条件 查询路由表local(ID 255)
32766: from all lookup main #32766 匹配任何条件 查询路由表main(ID 254)
32767: from all lookup default #32767 匹配任何条件 查询路由表default(ID 253)
不要混淆路由表和策略:规则指向路由表,多个规则可以引用一个路由表,而且某些路由表可以没有策略指向它。如果系统管理员删除了指向某个路由表的所有规则,这个表就没有用了,但是仍然存在,直到里面的所有路由都被删除,它才会消失。
路由表介绍
Linux系统可以同时存在256(0-255)个路由表,而且每个路由表都各自独立,互不相关。数据包在传输时是根据RPDB(路由策略数据库)内的策略决定数据包应该用哪个路由表传输的。
在默认情况下,系统有三个路由表,这三个路由表的功能如下:
local:路由表local包含本机路由及广播信息。例如,在本机上执行ssh 127.0.0.1时,就会参考这份路由表的内容,在正常情况下,只要配置好网卡的网络设置,就会自动生成local路由表的内容,我们应该也不必修改其内容。
main:使用传统命令route -n所看到的路由表就是main的内容。Linux系统在默认情况下使用这份路由表的内容来传输数据包,因此,其内容极为重要,在正常情况下,只要配置好网卡的网络设置,就会自动生成main路由表的内容。
default:最后是default路由表,这个路由表在默认情况下内容为空;除非有特别的要求,否则保持其内容为空即可。
route命令默认查询的是main路由表
[root@bogon ~]# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default bogon 0.0.0.0 UG 100 0 0 ens33
192.168.1.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
192.168.2.0 0.0.0.0 255.255.255.0 U 0 0 0 ens33
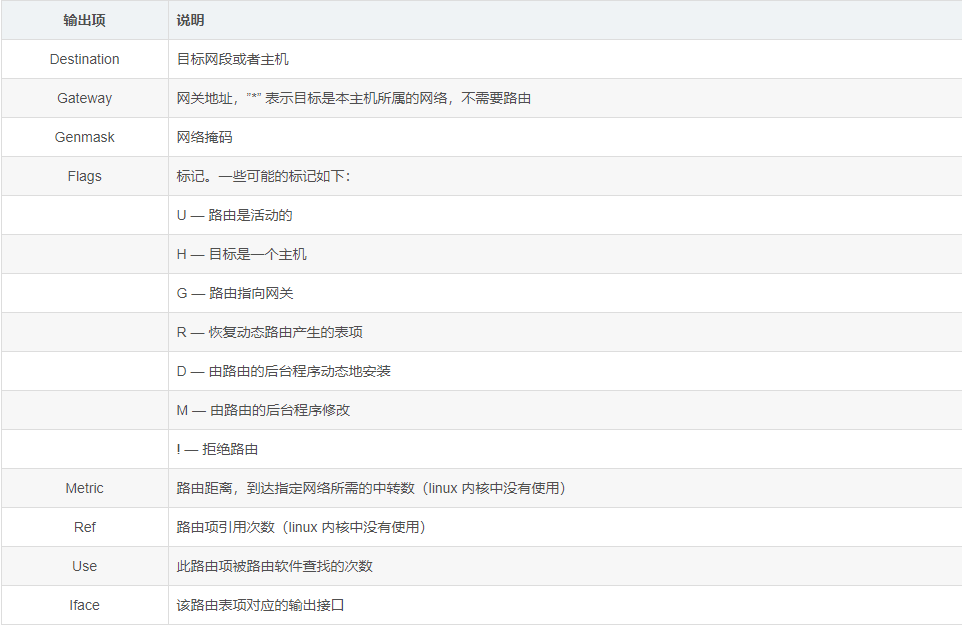
192.168.2.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33route 命令的输出项说明:
3种路由类型
1、主机路由
主机路由是路由选择表中指向单个IP地址或主机名的路由记录。主机路由的Flags字段为H。例如,在下面的示例中,本地主机通过IP地址192.168.1.1的路由器到达IP地址为10.0.0.10的主机。
Destination Gateway Genmask Flags Metric Ref Use Iface
----------- ------- ------- ----- ------ --- --- -----
10.0.0.10 192.168.1.1 255.255.255.255 UH 0 0 0 eth02、网络路由
网络路由是代表主机可以到达的网络。网络路由的Flags字段为N。例如,在下面的示例中,本地主机将发送到网络192.19.12的数据包转发到IP地址为192.168.1.1的路由器。
Destination Gateway Genmask Flags Metric Ref Use Iface
----------- ------- ------- ----- ----- --- --- -----
192.19.12 192.168.1.1 255.255.255.0 UN 0 0 0 eth03、默认路由
当主机不能在路由表中查找到目标主机的IP地址或网络路由时,数据包就被发送到默认路由(默认网关)上。默认路由的Flags字段为G。例如,在下面的示例中,默认路由是IP地址为192.168.1.1的路由器。
Destination Gateway Genmask Flags Metric Ref Use Iface
----------- ------- ------- ----- ------ --- --- -----
default 192.168.1.1 0.0.0.0 UG 0 0 0 eth0
route、ip route、ip rule命令
route命令
设置和查看路由表都可以用 route 命令,设置内核路由表的命令格式是:
# route [add|del] [-net|-host] target [netmask Nm] [gw Gw] [[dev] If]其中:
add : 添加一条路由规则;
del : 删除一条路由规则;
-net : 目的地址是一个网络;
-host : 目的地址是一个主机;
target : 目的网络或主机;
netmask : 目的地址的网络掩码;
gw : 路由数据包通过的网关;
dev : 为路由指定的网络接口。
添加到主机的路由
# route add -host 192.168.1.2 dev eth0:0
# route add -host 10.20.30.148 gw 10.20.30.40添加到网络的路由
# route add -net 10.20.30.40 netmask 255.255.255.248 eth0
# route add -net 10.20.30.48 netmask 255.255.255.248 gw 10.20.30.41
# route add -net 192.168.1.0/24 eth1添加默认路由
# route add default gw 192.168.1.1删除路由
# route del -host 192.168.1.2 dev eth0:0
# route del -host 10.20.30.148 gw 10.20.30.40
# route del -net 10.20.30.40 netmask 255.255.255.248 eth0
# route del -net 10.20.30.48 netmask 255.255.255.248 gw 10.20.30.41
# route del -net 192.168.1.0/24 eth1
# route del default gw 192.168.1.1ip rule
常使用ifconfig及route之类的命令,不过如果你准备开始使用linux强大的基于策略的路由机制,那么,就请不要使用这类工具了,因为这类工具根本无法用于功能强大的基于策略的路由机制,取而代之的工具是iproute
[root@bogon ~]# ip rule help
Usage: ip rule { add | del } SELECTOR ACTION
ip rule { flush }
ip rule [ list ]
SELECTOR := [ not ] [ from PREFIX ] [ to PREFIX ] [ tos TOS ] [ fwmark FWMARK[/MASK] ]
[ iif STRING ] [ oif STRING ] [ pref NUMBER ]
ACTION := [ table TABLE_ID ]
[ nat ADDRESS ]
[ realms [SRCREALM/]DSTREALM ]
[ goto NUMBER ]
TABLE_ID := [ local | main | default | NUMBER ]如果新加的路由在main表之外的路由表,则只有先添加规则后才能确定新的路由表的ID,有了新的路由表ID后,才能在该路由表中添加路由。
在添加规则时,需要先定义好优先级、条件及路由表ID,然后才可以添加规则。如下例:
#根据源地址决定路由表
ip rule add from 192.168.10.0/24 table 100
ip rule add from 192.168.20.20 table 110
#根据目的地址决定路由表
ip rule add to 192.168.30.0/24 table 120
ip rule add to 192.168.40.0/24 table 130
#根据网卡设备决定路由表
ip rule add dev eth0 table 140
ip rule add dev eth1 table 150
上面的路由表都是用100、110、120、130等数字表示的,时间一久难免自己也会忘记该路由表的作用,不过iproute提供了一个路由表和名称的对应表(/etc/iproute2/rt_tables),可以手动修改该表。
可以看到添加路由表100后,显示确实是100,在修改rt_tables的映射关系后(100映射到wangtong),ip rule show
ip命令来删除路由表
#根据明细条目删除
ip rule del from 192.168.10.10
#根据优先级删除
ip rule del prio 32765
#根据表名称来删除
ip rule del table wangtong注:各路由表中应当指明默认路由,尽量不回查路由表.路由添加完毕,即可在路由规则中应用