这几天在整理笔记过程发现关于redis缓存击穿在网上比较零散,就将相关资料从新梳理了一遍:
1.缓存穿透是什么
缓存穿透是指在使用缓存系统如redis时,特定的查询在缓存和数据库中都找不到结果,导致每次查询都要访问数据库,从而增加数据库的压力,降低系统的
性能。
当一个查询请求经过缓存系统时,缓存先检查是否有缓存的结果,如果有则直接返回给客户端,如果没有则查询数据库并将结果存入缓存后返回。但是,如果
查询的数据在数据库中不存在,那么每次查询都会通过缓存系统直接访问数据库,导致数据库无效查询增加,浪费了系统资源。
2.常见的缓存穿透情况
-
查询不存在的数据:当用户查询一个不存在的数据,例如某个不存在的用户ID,由于缓存中没有缓存该数据,每次查询都会失败并直接访问数据库。
-
恶意查询:如果攻击者故意发送大量不存在的请求,试图绕过缓存,并导致大量无效的数据库查询请求。
3.缓存穿透会带来的问题 :
增加数据库负载:由于缓存穿透导致大量无效的数据库查询操作,增加了数据库的负载,可能导致数据库性能下降。
击穿缓存:如果缓存中缓存了查询结果为空的键,恶意攻击者可以通过大量请求这些不存在的键,使缓存中的该键过期,从而导致后续请求都直接访问数据
库,形成缓存击穿.
4.解决缓存穿透问题方法
布隆过滤器(Bloom Filter):在查询前先通过布隆过滤器快速判断查询的数据是否存在,若不存在则不再访问缓存和数据库,减轻数据库压力。
空结果缓存:在缓存中存储空结果的键,可以避免缓存穿透,防止恶意攻击。
延迟双写:在查询到数据库不存在该数据时,在缓存中也写入一个空结果的占位符,设置较短的过期时间,以防止并发大量请求穿透缓存直接访问数据库。
异步更新缓存:当发现缓存和数据库中都不存在某个查询结果时,可以使用异步更新缓存的方式,先返回空结果给用户,然后通过后台任务去查询数据库并更
新缓存,提高查询的响应速度和系统的并发能力。
2、缓存击穿
1.缓存击穿是什么
在高并发场景下,同一时刻有大量请求同一条数据时,当这条数据在缓存中不存在时(即缓存未命中),所有请求同时去查询数据库。这种情况下,数据库会
瞬间受到大量请求的压力,导致性能瓶颈或系统崩溃。
缓存击穿问题也叫热点key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
缓存击穿与缓存雪崩有一定的区别。缓存雪崩是指许多数据同时过期,导致大量数据查询失败,从而造成数据库负载激增。而缓存击穿则是由于并发查同一条
数据而导致数据库压力瞬间增大。

差异失效时间,对于访问频繁的热点key,不设置过期时间
采用互斥锁,双检加锁策略更新
双检锁通常用于解决懒加载中的并发问题,即只有当数据在缓存中不存在时,才进行数据库查询,并且确保只有一个线程进行数据库查询
3、缓存雪崩
1.缓存雪崩是什么
缓存雪崩是指同一时间大面积的缓存失效,从而导致大量请求直接落到数据库上,造成数据库在短时间内承受大量请求,进而可能导致数据库崩溃。通常,缓
存雪崩可能由以下情况引起:
-
缓存统一过期:当大量缓存设置了相同的过期时间,且没有加以控制时,这些缓存会同时失效,导致大量请求直接访问数据库。
-
单点故障:如果Redis服务器出现故障,所有缓存都无法访问,这也会导致请求直接落到数据库上。
-
系统压力:系统承受的压力过大,导致缓存服务器崩溃,导致缓存失效。
Redis高可用:主从复制 + 哨兵机制
主从复制:通过将数据复制到多个从服务器,可以确保在主服务器出现问题时,从服务器继续提供服务。这样,数据的可用性和冗余性得以提高,避免单点故障导
致的缓存雪崩。
哨兵机制:Redis的哨兵机制负责监控Redis主从服务器的健康状态。一旦主服务器出现问题,哨兵将自动切换到备份服务器作为新的主服务器,从而保障数据的持
续可用。
分片集群:集群中有多个master,每个master保存不同数据,每个master都可以有多个slave节点,master之间通过ping监测彼此健康状态,客户端请求可以访
问集群任意节点,最终都会被转发到正确节点 ,需保证分片集群不能在同一时刻失效。
本地ehcache缓存 + Hystrix限流&降级
本地ehcache缓存:通过在应用程序中使用本地缓存(如ehcache)来缓存热点数据,可以缓解Redis服务器的压力。当Redis缓存失效时,本地缓存能够快速提供
备份数据,减少对数据库的直接压力。
Hystrix限流&降级:Hystrix可以对请求进行动态监控和管理,通过限流、熔断和降级等机制,确保系统在高压力下仍然能稳定运行,防止数据库过载。
缓存数据的过期时间设置随机
随机过期时间:为每一个缓存数据设置不同的过期时间,并保持一定的随机性。这样可以避免同一时间大量缓存数据同时过期,导致缓存雪崩现象。
缓存标记失效则更新数据缓存
缓存标记策略:为每个缓存数据增加相应的缓存标记,使数据逻辑上永不过期。只有当缓存标记失效时才会更新数据缓存。这种策略可以减少大规模缓存失效的概
率。
多级缓存:二级缓存更新一级缓存
多级缓存策略:采用多级缓存策略,比如在应用程序中使用本地缓存作为一级缓存,Redis缓存作为二级缓存。这样,当一级缓存失效时,可以通过二级缓存快速
更新一级缓存,保持数据的及时性和可用性。
第三方插件更新缓存:通过引入第三方插件(如RocketMQ)来协助数据同步和缓存更新。它们能够在数据源或二级缓存更新时,自动触发对应的缓存更新操作,
确保数据一致性。
使用热点数据预加载
预先将热点数据加载到缓存中,并设置较长的过期时间,可以避免在同一时间点大量请求直接访问数据库。可以根据业务需求,在系统启动或低峰期进行预热
操作,将热点数据提前加载到缓存中。
热点数据预加载可以提升系统的性能和响应速度,减轻数据库的负载。要注意的是,预加载操作可能会占用系统资源,因此需要合理安排预加载执行的时间和
频率,避免对系统正常业务的影响。另外,需要根据实际情况监控和调整预加载策略,以保持缓存数据的实时性和准确性。
4、布隆过滤器
布隆过滤器(Bloom Filter)是 1970 年由布隆提出的,是一种非常节省空间的概率数据结构,运行速度快,占用内存小,但是有一定的误判率且无法删除元
素。它实际上是一个很长的二进制向量和一系列随机映射函数组成,主要用于判断一个元素是否在一个集合中。
通常我们都会遇到判断一个元素是否在某个集合中的业务场景,这个时候我们可能都是采用 HashMap的Put方法或者其他集合将数据保存起来,然后进行比
较确定,但是如果元素很多的情况下,采用这种方式就会非常浪费空间,最终达到瓶颈,检索速度也会越来越慢,这时布隆过滤器(Bloom Filter)就应运而生了。
布隆过滤器的优点:
支持海量数据场景下高效判断元素是否存在
布隆过滤器存储空间小,并且节省空间,不存储数据本身,仅存储hash结果取模运算后的位标记
不存储数据本身,比较适合某些保密场景
布隆过滤器的缺点:
不存储数据本身,所以只能添加但不可删除,因为删掉元素会导致误判率增加
由于存在hash碰撞,匹配结果如果是“存在于过滤器中”,实际不一定存在
当容量快满时,hash碰撞的概率变大,插入、查询的错误率也就随之增加了。
布隆过滤器中一个元素如果判断结果为存在的时候元素不一定存在,但是判断结果为不存在的时候则一定不存在。因此,布隆过滤器不适合那些对结果必须精
准的应用场景。
布隆过滤器适合的场景
-
区块链中使用布隆过滤器来加快钱包同步;以太坊使用布隆过滤器用于快速查询以太坊区块链的日志
-
数据库防止穿库,Google Bigtable,HBase 和 Cassandra 以及 Postgresql 使用BloomFilter来减少不存在的行或列的磁盘查找。避免代价高昂的磁盘查找会
-
大大提高数据库查询操作的性能。
-
判断用户是否阅读过某一个视频或者文章,类似抖音,刷过的视频往下滑动不再刷到,可能会导致一定的误判,但不会让用户看到重复的内容网页爬虫对URL
-
去重,采用布隆过滤器来对已经爬取过的URL进行存储,这样在进行下一次爬取的时候就可以判断出这个URL是否爬取过了使用布隆过滤器来做黑名单过滤,针对
-
不同的用户是否存入白名单或者黑名单,虽然有一定的误判,但是在一定程度上还是很好的解决问题缓存击穿场景,一般判断用户是否在缓存中,如果存在则
直接返回结果,不存在则查询数据库,如果来一波冷数据,会导致缓存大量击穿,造成雪崩效应,这时候可以用布隆过滤器当缓存的索引,只有在布隆过滤器
中,才去查询缓存,如果没查询到则穿透到数据库查询。如果不在布隆过滤器中,则直接返回,会造成一定程度的误判
-
WEB拦截器,如果相同请求则拦截,防止重复被攻击。用户第一次请求,将请求参数放入布隆过滤器中,当第二次请求时,先判断请求参数是否被布隆过滤器
命中。可以提高缓存命中率。Squid 网页代理缓存服务器在 cache digests 中就使用了布隆过滤器。Google Chrome浏览器使用了布隆过滤器加速安全浏览服务。
-
Google 著名的分布式数据库 Bigtable 使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的IO次数。
-
Squid 网页代理缓存服务器在 cache digests 中使用了也布隆过滤器。
-
Venti 文档存储系统也采用布隆过滤器来检测先前存储的数据。
-
SPIN 模型检测器也使用布隆过滤器在大规模验证问题时跟踪可达状态空间。
-
Google Chrome浏览器使用了布隆过滤器加速安全浏览服务。
如果允许误判率的话,可以使用布隆过滤器,只有你想不到的,没有你做不到的
布隆过滤器原理
数据结构
布隆过滤器是由一个固定大小的二进制向量或者(bitmap)和一系列映射函数组成的。
对于长度为 m 的位数组,在初始状态时,它所有位置都被置为0,如下图所示:

位数组中的每个元素都只占用 1 bit ,并且数组中元素只能是 0 或者 1。这样申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte =
125000/1024 KB ≈ 122KB 的空间。
增加元素
当一个元素加入布隆过滤器中的时候,会进行如下操作:
-
使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)
-
根据得到的哈希值,在位数组中把对应下标的值置为 1
如下图所示:
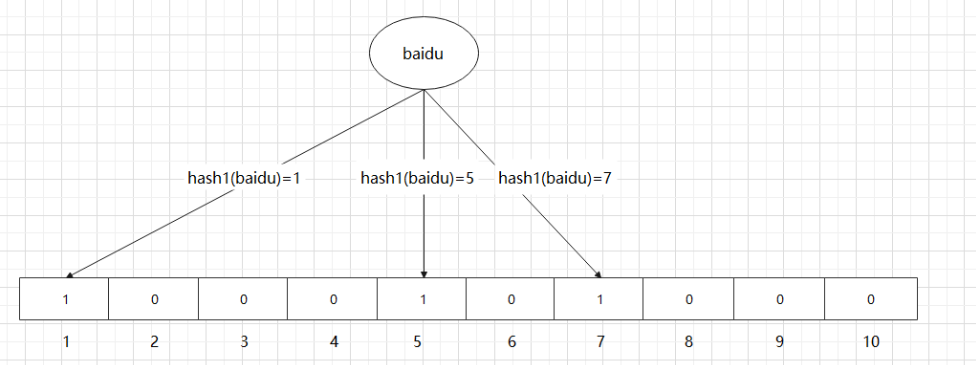
接着再添加一个值 “xinlang”,哈希函数的值是3、5、8,如下图所示:
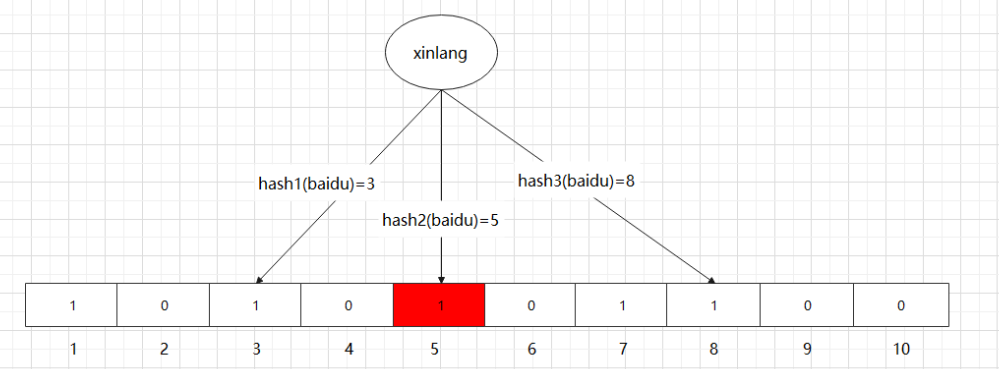
这里需要注意的是,5 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此被覆盖了。
查询元素
-
对给定元素再次进行相同的哈希计算
-
得到哈希值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值存在布隆过滤器当中,如果存在一个值不为 1,说明该元素不在布隆过
滤器中
例如我们查询 “cunzai” 这个值是否存在,哈希函数返回了 1、5、8三个值
如下图所示:
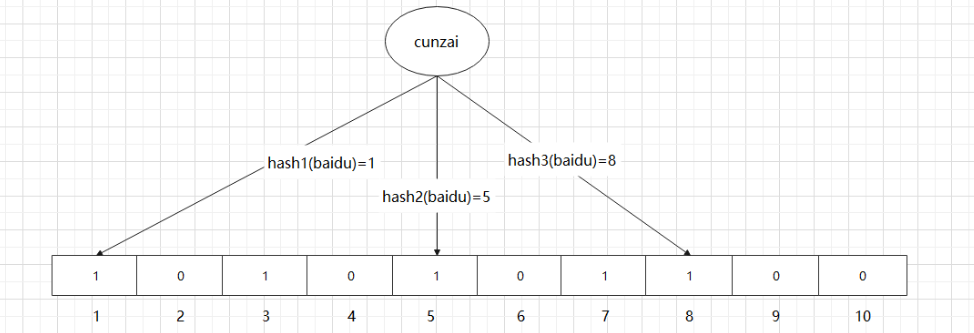
结果得到三个 1 ,说明 “cunzai” 是有可能存在的。
为什么说是可能存在,而不是一定存在呢?主要分为以下几种情况:
因为映射函数本身就是散列函数,散列函数是会有碰撞的情况发生。
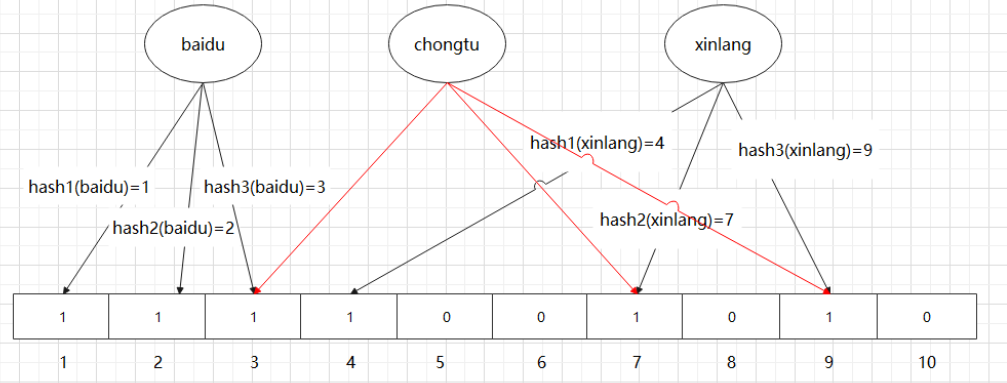
情况1:一个字符串可能是 “chongtu” 经过相同的三个映射函数运算得到的三个点跟 “xinlang” 是一样的,这种情况下我们就说出现了误判 情况2: “chongtu” 经过运算得到三个点位上的 1 是两个不同的变量经过运算后得到的,这也不能证明字符串 “chongtu” 是一定存在的。
Google开源的Guava自带布隆过滤器
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version>
</dependency>
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 5000000);
for (int i = 0; i < 5000000; i++) {
bloomFilter.put(i);
}
long start = System.nanoTime();
if (bloomFilter.mightContain(500000)) {
System.out.println("成功过滤到500000");
}
long end = System.nanoTime();
System.out.println("布隆过滤器消耗时间"+(end - start)/1000000L+"毫秒");
Redisson实现的布隆过滤器
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.6</version>
</dependency>
在RedisConfig加入配置类
("${spring.redis.host}")
private String host;
("${spring.redis.port}")
private String port;
public RedissonClient redisson() {
//创建配置
Config config = new Config();
config.useSingleServer().setAddress("redis://" + host + ":" + port);
//根据config创建出RedissonClient实例
return Redisson.create(config);
}
public class ObjectService {
RedissonClient redissonClient;
private RBloomFilter<Integer> bloomFilter = null;
public Object findById(Integer id) {
// bloomFilter中不存在该key,为非法访问
if (!bloomFilter.contains(id)) {
System.out.println("所要查询的数据既不在缓存中,也不在数据库中,为非法key");
return null;
}
// 不是非法访问,可以访问数据库
System.out.println("数据库中得到数据*****");
return objectDAO.findById(id);
}
public Integer add(Object object) {
objectDAO.insert(object);
// 新生成key的加入布隆过滤器,此key从此合法
bloomFilter.add(object.getId());
return objectDAO.getId();
}
}