分词器Text Analysis
分词器基础
基本概念
分词器官方称之为文本分析器,顾名思义,是对文本进行分析处理的一种手段,基本处理逻辑为按照预先制定的分词规则,把原始文档分割成若干更小粒度的词项,粒度大小取决于分词器规则。
分词器发展
分词器的处理过程发发展经过 Index Time 和 Search Time两个时期。
Index Time:文档写入并创建倒排索引时期,其分词逻辑取决于映射参数 analyzer。
Search Time:搜索发生时期,其分词仅对搜索词产生作用。
分词器的组成
切词器(Tokenizer):用于定义切词(分词)逻辑
词项过滤器(Token Filter):用于对分词之后的单个词项的处理逻辑
字符过滤器(Character Filter):用于处理单个字符
put /products_analyer
{
"settings":{
"analysis":{
"char_filter":{},
"filter":{},
"tokenizer":{}
}
}
}注意:
分词器不会对源数据造成任何影响,分词仅仅是对倒排素引或者搜索词的行为。
文档归一化处理:Normalization
Processors
大小写统一
时态转换
停用词:如一些语气词、介词等在大多数场景下均无搜索意义
注意:文档归一化处理的场景不仅限于以上几点,具体取决于分词器如何定义。
意义
增加召回率
减小匹配次数,进而提高查询性能
_analyzer API
_analyzer API可以用来查看指定分词器的分词结果。
语法如下:
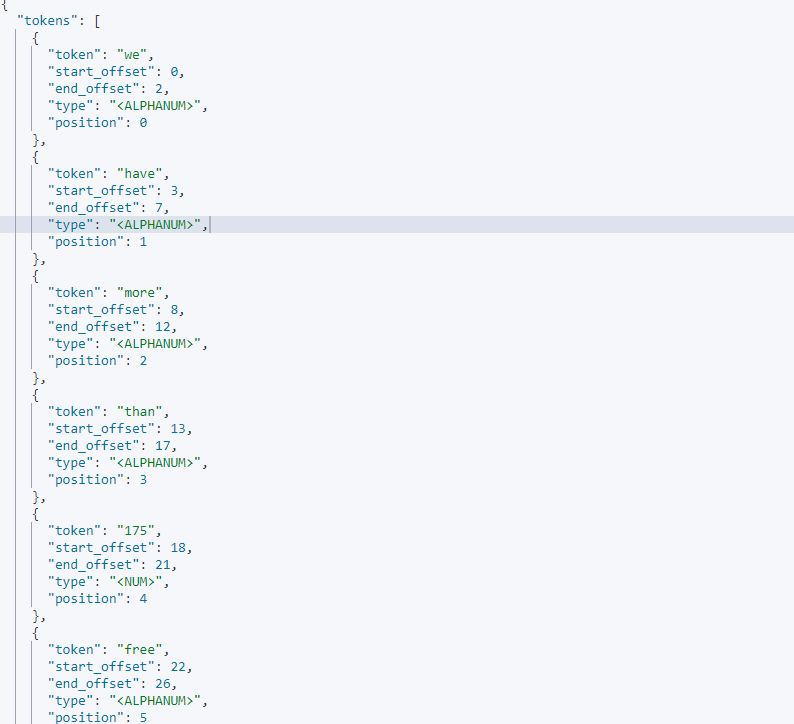
GET /_analyze
{
"text": ["We have more than 175 free activities to help you practise your English Search"],
"analyzer":"english"
}
切词器:Tokenizer
tokenizer是分词器的核心组成部分之一,其主要作用是分词,或称之为切词。主要用来对原始文本进行细粒度拆分。拆分之后的每一个部分称之为一个Term,或称之为一个词项。
可以把切词器理解为预定义的切词规则。
官方内置了很多种切词器,默认的切词器位standard。
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis.html
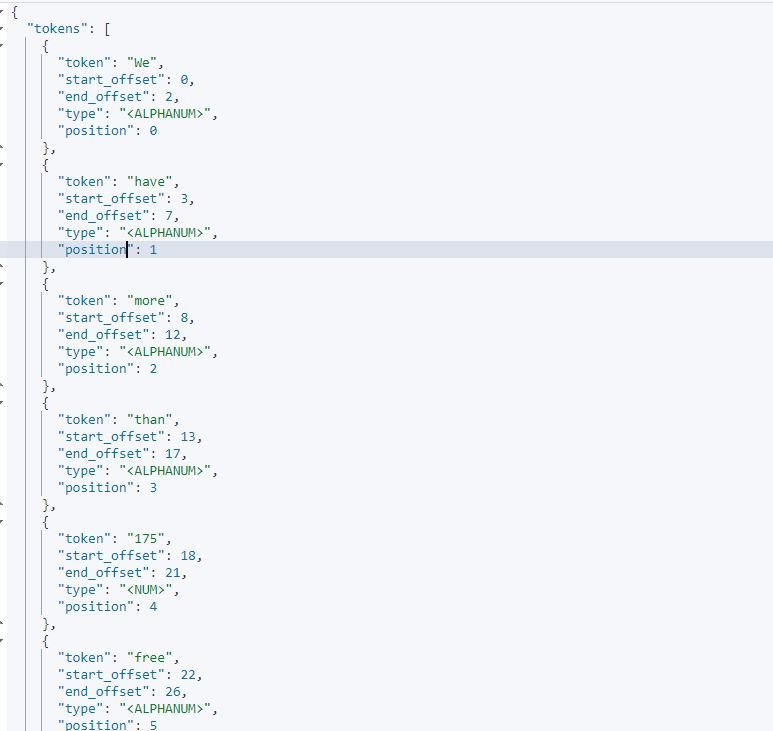
GET _analyze
{
"tokenizer": "standard",
"text": ["We have more than 175 free activities to help you practise your English Search"]
}
词项过滤器:Token Filter
简介
词项过滤器用来处理切词完成之后的词项,例如把大小写转换,删除停用词或同义词处理等。
官方同样预留了很多词项过滤器,基本可以满足日常开发的需要。当然也是支持第三方也自行开发的。
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenfilters.html

Lowercase 和 Uppercase
GET _analyze
{
"filter": ["lowercase"],
"text": "We have more than 175 free activities to help you practise your English Search"
}
GET _analyze
{
"tokenizer": "standard",
"filter": ["uppercase"],
"text": ["We have more than 175 free activities to help you practise your English Search"]
}停用词
在切词完成之后,会被干掉词项,即停用词。停用词可以自定义
英文停用词(english):a, an, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on, or, such, that, the, their, then, there, these, they, this, to, was, will, with。
中日韩停用词(_cjk): a, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on, or, s, such, t, that, the, their, then, there, these, they, this, to, was, will, with, www
GET _analyze
{
"tokenizer": "standard",
"filter": ["stop"],
"text": ["I am grateful to Josef Essberger for the 7 Secrets. They are informative and sharp.- Andrey Kochanov, Learner of English, Russia"]
}自定义停用词
PUT custom_token_filter_stop
{
"settings": {
"analysis": {
"filter": {
"custom_filter": {
"type": "stop",
"stopwords": [
"are"
],
"ignore_case": true
}
}
}
}
}
GET custom_token_filter_stop/_analyze
{
"tokenizer": "standard",
"filter": ["custom_filter"],
"text": ["I am grateful to Josef Essberger for the 7 Secrets. They are informative and sharp.- Andrey Kochanov, Learner of English, Russia"]
}同义词
同义词定义规则
a,b,c => d:这种方式,a、b、c 会被 d 替代。
a,b,c,d:这种方式下,a、b、c、d 是等价的。
同义词定义方式
内联:直接在synonym内部声明规则
文件:在文件中定义规则,文件相对顶级目录为ES的Config文件夹。
"c_synonym": {
"type": "synonym",
"synonyms": ["good, nice => excellent"] //good, nice, excellent
}
PUT custom_t_f_synonym
{
"settings": {
"analysis":{
"filter": {
"custom_synonym": {
"type": "synonym",
"synonyms_path":"analysis/synonyms.txt" #文件相对顶级目录为ES的Config文件夹
"synonyms": [
"a,b,c => d"
],
}
}
}
}
}
GET custom_t_f_synonym/_analyze
{
"tokenizer": "standard",
"filter": ["custom_synonym"],
"text": ["I am grateful to Josef Essberger for the 7 Secrets. They are informative and sharp.- Andrey Kochanov, Learner of English, Russia"]
}字符过滤器:Character Filter
基本概念
分词之前的预处理,过滤无用字符
基本用法
语法
PUT /<index>
{
"settings":{
"analysis":{
"char_filter": {
"custom_char_filter":
{
"type":"<char_filter_type>"
}
}
}
}
}参数:
type:使用的字符过滤器类型名称,可配置以下值
html_strip
mapping
pattern_replace
官方支持的三种Char Filter
HTML标签过滤器:HTML Strip Character Filter
字符过滤器会去除HTML标签和转义HTML元素,如**、&**
参数:
escaped_tags: 需要保留的 html 标签
delete product_desc
PUT /product_desc
{
"settings":{
"analysis":{
"char_filter": {
"html_char_filter":{
"type":"html_strip",
"escaped_tags":["a"]
}
} }
}
}
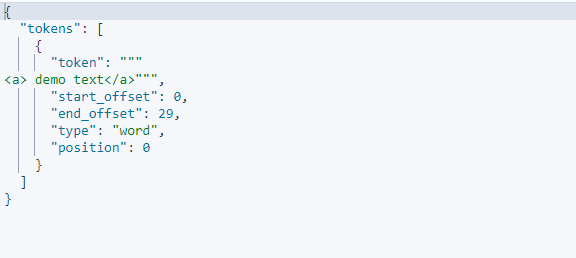
get /product_desc/_analyze
{
//"tokenizer": "standard",
"char_filter": ["html_char_filter"],
"text": ["<html><a> demo text</a></html"]
}
#mapping
delete product_desc
PUT /product_desc
{
"settings":{
"analysis":{
"char_filter": {
"custom_mapping":{
"type":"mapping",
"escaped_tags":["a"]
}
} }
}
}
get /product_desc/_analyze
{
"tokenizer": "standard", //
"char_filter": ["html_char_filter"],
"text": ["<html><a> demo text</a></html"]
}
delete product_desc
PUT /product_desc
{
"settings":{
"analysis":{
"char_filter": {
"mapping":{
"type":"pattern_replace",
"escaped_tags":["a"]
}
} }
}
}
get /product_desc/_analyze
{
"tokenizer": "standard",
"char_filter": ["html_char_filter"],
"text": ["<html><a> demo text</a></html"]
}字符映射过滤器:Mapping Character Filter
通过定义映替换为规则,把特定字符替换为指定字符
delete custom_mapping_filter
PUT custom_mapping_filter
{
"settings": {
"analysis":{
"char_filter": {
"my_char_filter": {
"type": "mapping",// mapping 代表使用字符映射过滤器
"mappings": [ // 数组中规定的字符会被等价替换为 => 指定的字符
"滚 => *",
"垃 => *",
"圾 => *"
]
}
}
}
}
}
GET custom_mapping_filter/_analyze
{
"tokenizer":"standard",
"char_filter":["my_char_filter"],
"text":"你就是个垃圾!滚"
}
GET custom_mapping_filter/_analyze
{
"char_filter":["my_char_filter"],
"text":"你就是个垃圾!滚"
}正则替换过滤器:Pattern Replace Character Filter
PUT custom_pattern_replace_filter
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter": {
"type": "pattern_replace",
"pattern": """(\d{3})\d{4}(\d{4})""",
"replacement": "$1****$2"
}
}
}
}
}
GET custom_pattern_replace_filter/_analyze
{
"char_filter": [
"my_char_filter"
],
"text": "您的手机号是18868686688"
}内置分词器
内置分词器:
Standard:默认分词器,中文支持的不理想,会逐字拆分。参数值为:standard
Pattern:以正则匹配分隔符,把文本拆分成若干词项。参数值为:pattern
Simple:除了英文单词和字母,其他统统过滤掉,参数值为:simple
Whitespace:以空白符分隔,不会改变大小写,参数值为:whitespace
Keyword:可以理解为不做任何操作的分明器,会保留原有文本的所有属性,参数值为:keyword
Stop:分词规则和Simple Analyzer相同,但是增加了对停用词的支持。参数值为:stop
Language Analyzer:支持全球三十多种主流语言。
Fingerprint:一种特殊领域分词器,不常用
自定义分词器:Custom Analyzer
三个基本组件的使用规则
如果ES内置分词器无法满足需要,可以通过对切词器、词项过滤器、字符过滤器三个组件的自由组合来自定义分词器。在使用分词器时候需要注意必须满足以下要求:
Tokenizer:必须包含一个并且只能指定一个切词器,即必须指定分词器的切词规则。
Token Filter:可以不指定词项过滤器,也可以指定多个词项过滤器
Char Filter:可以不指定字符过滤器,也可以指定多个字符过滤器
type 参数
PUT <index_name>
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer":{ // 自定义分词器名称
"type": ""// 接受 ES 内置分词器,也可以配置为 custom 从而自定义分词
}
}
}
}
}type:可选值为第6节中指定的分词器,或者指定为custom来自定义分词器
示例
PUT custom_analyzer
{
"settings": {
"analysis": {
"analyzer": {
"custom_analyzer":{ // 自定义分词器名称
"type": "custom",// 接受 ES 内置分词器,也可以配置为 custom 从而自定义分词
"tokenizer":"custom_tokenizer",
"filter":["custom_filter"],
"char_filter":["custom_html_filter"]
}
},
"tokenizer": {
"custom_tokenizer":{
"type":"pattern",
"pattern":[",!.?"]
}
},
"char_filter": {
"custom_html_filter":{
"type":"html_strip",
"escaped_tags":["a"]
}
},
"filter": {
"custom_filter": {
"type": "stop",
"stopwords": [
"are"
],
"ignore_case": true
}
}
}
}
}
PUT custom_analyzer/_mapping
{
"properties": {
"title": {
"type": "text",
"analyzer":"custom_analyzer"
}
}
}
GET custom_analyzer/_analyze
{
"analyzer":"custom_analyzer",
"text":["are you ok? <html><a> hello world!</a>"]
}analyzer 和 search_analyzer
analyzer:为字段指定的分词器,仅对文本字段生效
search_analyzer:搜索时分词器,即作用于搜索词的分词器。
当search_analyzer未指定时,其缺省值为analyzer,若analyzer未指定,search_analyzer和analyzer的值都为standard
PUT custom_analyzer/_mapping
{
"properties": {
"title": {
"type": "text",
"analyzer":"custom_analyzer",
"search_analyzer":"standard"
}
}
}文档归一化器:Normalizers
概念
在Elasticsearch中,文档归一化器(normalizer)用于在索引时对字段进行标准化处理,以确保字段值的比较是一致的。归一化器通常用于分析字符串字段,比如排序或聚合查询中的关键字(keyword)字段.
normalizer与analyzer的作用类似,都是对字段进行处理,但是不同之处在于normalizer不会对字段进行分词,也就是说 normalizer没有tokenizer
所以normalizer是作用于keyword类型的字段的,相当于我们需要给keyword类型字段做一个额外的处理时,比如转换为小写时就可以用到normalizer
注意事项
normalizer只能用于keyword类型
normalizer设置的字段不能被分词
PUT custom_normalizer
{
"settings": {
"analysis": {
"analyzer": {
"custom_analyzer": {
"filter": [
"uppercase"
],
"tokenizer": "standard"
}
},
"normalizer": {
"custom_normalizer": {
"type": "custom",
"filter": [
"uppercase"
],
"char_filter": []
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "keyword",
"normalizer": "custom_normalizer"
}
}
}
}
PUT custom_normalizer/_doc/1
{
"name": "ElasticSearch"
}
PUT custom_normalizer/_doc/2
{
"name": "ELASTICSEARCH"
}
GET custom_normalizer/_search
{
"query": {
"match": {
"name": "elasticsearch"
}
}
}中文分词器
安装和部署
下载
IK下载地址:https://github.com/medcl/elasticsearch-analysis-ik
https://release.infinilabs.com/analysis-ik/stable/
安装
方式一:
创建插件文件夹:cd {es-root-path}/plugins/ && mkdir ik
将插件解压缩到文件夹:{es-root-path}/plugins/ik
重新启动 ES 服务
方式二
./bin/elasticsearch-plugin install file:///path/to/elasticsearch-analysis-ik-版本.zip验证
GET _analyze
{
"analyzer" : "ik_max_word",
"text" : ["我学习 Elasticsearch 选择 Elastic 开源社区"]
}
GET _analyze
{
"analyzer" : "ik_smart",
"text" : ["我学习 Elasticsearch 选择 Elastic 开源社区"]
}备注:https://www.hanlp.com/semantics/dashboard/index
https://github.com/hankcs/HanLP
基本使用
词库文件描述
IKAnalyzer.cfg.xml: IK分词配置文件
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!——配置扩展字典 ——> <entry key="ext_dict"></entry> <!—— 配置扩展停止词字典——> <entry key="ext_stopwords"></entry> <!—— 配置远程扩展字典 ——> <!—— <entry key="remote_ext_dict">words_location</entry> ——> <!—— 配置远程扩展停止词字典——> <!—— <entry key="remote_ext_stopwords">words_location</entry> ——> </properties>主词典:main.dic
英文停用词:stopword.dic,不会建立在倒排索引中
特殊词库:
quantifier.dic:特殊词库:计量单位等
suffix.dic:特殊词库:行政单位
surname.dic:特殊词库:百家姓
preposition:特殊词库:语气词
自定义词库:网络词汇、流行词、特定领域词库等。
ik 提供的两种 analyzer:
ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
GET _analyze
{
"analyzer" : "ik_max_word",
"text" : ["我正在学习中华人民共和国国歌"]
}
GET _analyze
{
"analyzer" : "ik_smart",
"text" : ["我正在学习中华人民共和国国歌"]
}基于本地词库扩展
配置文件:IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<!--扩展词库的根目录为ik/config-->
<comment>IK Analyzer 自定义扩展配置</comment>
<!--配置自定义的扩展字典,多个词库文件路径使用;隔开。-->
<entry key="ext_dict">custom/es_ext.dic;custom/es_buzzword.dic</entry>
<!--配置自定义扩展停止词典,多个词库文件路径使用;隔开。 -->
<entry key="ext_stopwords"></entry>
<!--配置自定义远程扩展字典,多个词库文件路径使用;隔开。 -->
<!- -<entry key="remote_ext_dict">words_location</entry> -->
<!--配置自定义扩展停止词典,多个词库文件路径使用;隔开。-->
<!- -<entry key="remote_ext_stopwords">words_location</entry> --->
</properties>
扩展词库的根目录为ik/config
多个词库文件路径使用;隔开
基于远程词库热更新
词库配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<!--扩展词库的根目录为ik/config-->
<comment>IK Analyzer 自定义扩展配置</comment>
<!--配置自定义的扩展字典,多个词库文件路径使用;隔开。-->
<entry key="ext_dict">custom/es_ext.dic;custom/es_buzzword.dic</entry>
<!--配置自定义扩展停止词典,多个词库文件路径使用;隔开。 -->
<entry key="ext_stopwords"></entry>
<!--配置自定义远程扩展字典,多个词库文件路径使用;隔开。 -->
<!- -<entry key="remote_ext_dict">>http://127.0.0.1/api/hotWord?wordLib=1</entry> -->
<!--配置自定义扩展停止词典,多个词库文件路径使用;隔开。-->
<!- -<entry key="remote_ext_stopwords">http://127.0.0.1/api/hotWord?wordLib=0</entry> --->
</properties>
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
@RestController
public class HotWordsController {
// 假设你的词典文件存放在这个路径
private static final String DICT_PATH = "/opt/es/dict/hot/";
private static final String STOPWORDS_PATH = "/opt/es/dict/stopwords/";
/**
* 获取热更新词典或停用词
*
* @param wordLib 词典类型,1为词典,0为停用词
* @return 词库内容
*/
@GetMapping("/api/hotWord")
public String getHotWords(@RequestParam("wordLib") Integer wordLib) {
if (wordLib == null) {
return "Invalid parameter";
}
String wordContent;
try {
if (wordLib == 1) {
// 返回自定义词典内容
wordContent = new String(Files.readAllBytes(Paths.get(DICT_PATH + "custom.dic")));
} else {
// 返回停用词内容
wordContent = new String(Files.readAllBytes(Paths.get(STOPWORDS_PATH + "custom_stopwords.dic")));
}
} catch (IOException e) {
// 日志记录异常
e.printStackTrace();
return "Error reading word library";
}
return wordContent;
}
}
官方要求
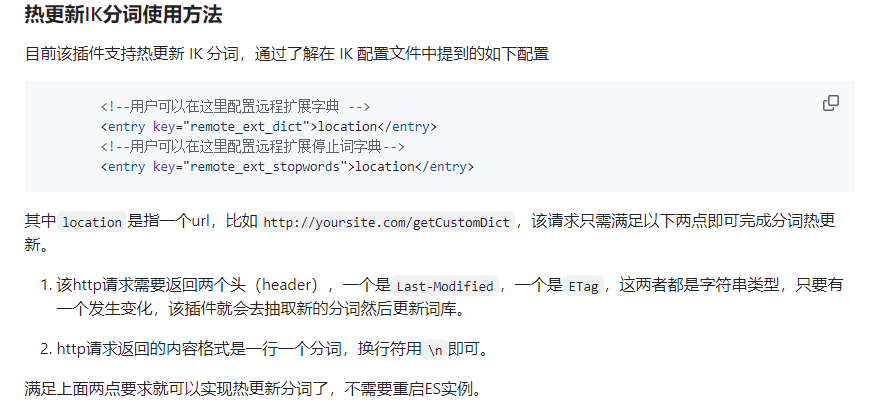
curl -XGET "http://localhost:9200/<index>/_analyze" -H 'Content-Type: application/json' -d'
{
"text":"中华人民共和国国歌","tokenizer": "ik_max_word"
}'优缺点
优点:
上手简单
支持热更新
低代码
缺点:
词库的管理不方便,要操作直接操作磁盘文件,检索页很麻烦
文件的读写没有专门的优化性能不好
多一层接口调用和网络传输
基于MySQL的词库热更新
项目源码
1、下载es-ik;源代码
2、org.wltea.analyzer.dic.Dictionary
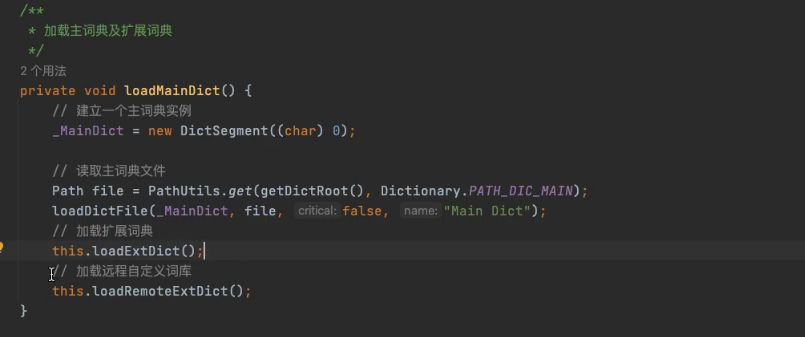
增加mysql加载
在config目录中增加jdbc属性文件
jdbc-reload.properties
jdbc.url=jdbc:mysql://1ocalhost:3306/es-ik?serverTimezone=UTC
jdbc.user=root
jdbc.password=123456
jdbc.reload.sql=select word from ik_es_extword
jdbc.reload.stopword.sql=select stopword as word from ik_es_stopword
jdbc.reload.interval=7200代码:
在Dictionary类中增加loadDbExtDict、loadDbStoptDict
void loadDbExtDict{
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
Path file = PathUtils.get(getDictRoot()), "jdbc-reload.properties");
prop.load(new FileInputStream(file.toFile()));
conn = DriverManager.getConnection(prop.getProperty("jdbc.url"),prop.getProperty("jdbc.user"),prop.getProperty("jdbc.password"));
stmt = conn.createStatement();
rs = stmt.executeQuery(prop.getProperty("jdbc.reload.sql"));
while (rs.next()){
String word = rs.getString("word");
_MainDict.fillSegment(word.trim().toCharArray());
}
Thread.sleep(Integer.valueOf(String.valueOf(prop.get("jdbc.reload.interval”))));
} catch (Exception e) {
logger.error(message: “error:”,e); } finally {
}finally{
try {
rs.close();
} catch (SQLException e)
{
throw new RuntimeException(e);
}
if (stmt!=null){
try {
stmt.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
if(conn!=null){
try {
conn.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
void loadDbStoptDict{
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
Path file = PathUtils.get(getDictRoot()), "jdbc-reload.properties");
prop.load(new FileInputStream(file.toFile()));
conn = DriverManager.getConnection(prop.getProperty("jdbc.url"),prop.getProperty("jdbc.user"),prop.getProperty("jdbc.password"));
stmt = conn.createStatement();
rs = stmt.executeQuery(prop.getProperty("jdbc.reload.stopword.sql"));
while (rs.next()){
String word = rs.getString("word");
_MainDict.fillSegment(word.trim().toCharArray());
}
Thread.sleep(Integer.valueOf(String.valueOf(prop.get("jdbc.reload.interval”))));
} catch (Exception e) {
logger.error(message: “error:”,e); } finally {
}finally{
try {
rs.close();
} catch (SQLException e)
{
throw new RuntimeException(e);
}
if (stmt!=null){
try {
stmt.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
if(conn!=null){
try {
conn.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
在该代码中加以上方法
加入mysql-jdbc驱动
常见异常处理
1、驱动版本不兼容
MySQL 驱动版本兼容性
https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-versions.html
https://dev.mysql.com/doc/connector-j/5.1/en/connector-j-versions.html
# 驱动下载地址
https://mvnrepository.com/artifact/mysql/mysql-connector-java总结
注意:char filter 和 token filter 仅对倒排索引产生作用,对源数据没有任何影响。